hot 100
1 两数之和
- 时间复杂度O(n),空间O(n)
- 哈希map, find, count(时间复杂度都为O(1), 最坏情况为O(n))
2 两数相加 链表
- 初始化pre,每次相加包括pre, 整除10更新pre
3 无重复字符的最长子串
- 滑动窗口+hashset
4 寻找两个正序数组的中位数
- 二分查找,边界,各种情况分析,易错,复习
5 最长回文子串
- 从中心往两边扩展,分为偶数和奇数情况
10 正则表达式匹配
- 动态规划
11 盛最多水的容器
- 双指针,策略:矮的往前走可能变大,高的往前走,由于高度还是矮的决定所以只能变小,所以最终,每次选择矮的一侧往前走,并更新面积
15 三数之和
- 排序+双指针, 三层循环的内两层可以改为相向逼近的双指针
- 注意内层元素大于等于外层,但内外层可以可以元素相同,同层不能元素相同,还有双指针相遇时可以提前结束循环,细节很多,易错,复习
17 电话号码的字母组合
- 回溯,递归
19 删除链表的倒数第 N 个结点
- 官方要求一次遍历,但官方解答却是快慢指针,仍然是两次遍历
- 直接遍历一次,并用数组存下每个节点指针,最有用数组直接O(1)就可以索引到倒数n+1个节点,实现删除了
20 有效的括号
- 栈,奇数个直接return false
21 合并两个有序链表
- 归并,注意定义一个空的节点pre,便于编程
22 括号生成
- 回溯,需要强化思路,复习
23 并K个升序链表
- 优先队列
31 下一个排列
32 最长有效括号
33 搜索旋转排序数组
- 看官方二分搜索的写法,更加清晰
- 每次二分,总有一部分是有序的,若target在有序中,则正常二分,若不在,则是一个子问题,继续二分
34 在排序数组中查找元素的第一个和最后一个位置
- 学习如何二分查找找到第一个大于等于target的位置,第一个大于target的位置
39 组合总和
- 回溯
42 接雨水
- 不会,看解析,先理解动态规划,再理解双指针
- 复习复习复习
46 全排列
- 回溯,swap方式动态维护数组,递归到底,维护的数组就是最终结果,直接加入res即可,不用额外维护一个排序结果的数组
48 旋转图像
49 字母异位词分组
- 字母排序+ hashmap
53 最大子数组和
- 动态规划: f[i] = max(nums[i], f[i-1]) // 如果此时取了nums[i]则表示前面的舍弃,新的区间从i开始
55 跳跃游戏
- 贪心,看代码更易理解
56 合并区间
62 不同路径
- 坐标型动态规划
64 最小路径和
- 坐标型动态规划
70 爬楼梯
- 动态规划
72 编辑距离
- 动态规划
75 颜色分类
- 三路快排思想
76 最小覆盖子串
- 滑动窗口 + hashmap记录字符满足个数,并记录
78 子集
- 回溯
79 单词搜索
- 递归回溯,开标记数组
84 柱状图中最大的矩形
- 单调栈,第一次学习,复习
85 最大矩形
- 84升级版,复习
94 二叉树的中序遍历
- 递归和非递归,栈
96 不同的二叉搜索树
- 动态规划,不太懂,复习
98 验证二叉搜索树
- 注意利用性质
- 二叉搜索树中序遍历正好是升序
- 递归,自顶向下,传递左子树和右子树的范围
- 注意利用性质
101 对称二叉树
- 递归和迭代写法都不是很熟悉,需要复习复习
102 二叉树的层序遍历
- 用队列长度记录每层的元素个数,从而分层
104 二叉树的最大深度
- dfs,bfs
105 从前序与中序遍历序列构造二叉树 待写
- 递归构建,有难度,不熟悉,复习
- 先序遍历的第一个元素就是中序遍历的中间位置,定位到中序遍历的中间位置,则可以将左右分为左子树和右子树,而左子树确定后可以确定长度,又可以反过来让先序遍历的数组明确左子树和右子树的区间,然后进行递归划分
- 非递归写法待学习
- 递归构建,有难度,不熟悉,复习
114 二叉树展开为链表 待写
- 先前序遍历搜集顺序到数组中,再通过数组顺序构建链表
- 先序遍历过程中展开为链表,利用栈
121 买卖股票的最佳时机
- 记录左边最小值,遍历一次
124 二叉树中的最大路径和
- 递归,官方解答思路更清晰
128 最长连续序列 待写
- 哈希
136 只出现一次的数字 待写
- 异或运算,性质,,,学习,记忆,异或运算符号
139 单词拆分
- 动态规划
141 环形链表
- 快慢指针
142 环形链表 II
- 141升级,巧妙,记忆
146 LRU 缓存
- 直接用list,stl的list就是双向指针
1 | mp.erase(ls.back().first); // 先mp移除,因为先ls,这里还要使用ls |
- 148 排序链表
- 归并排序,注意指针的移动,易错,复习
- 152 乘积最大子数组
- 动态规划,类似53最大子数组和
- 153 最小栈
- 两个栈
- 160 相交链表
- 只考虑了相交则相交之后完全共用的情况,但答案解析比较巧妙,待复习
- 169 多数元素
- 巧妙,复习
- 核心点:任意删除一对不同的数字,删除后的数组仍然满足存在多数元素的性质
- 198 打家劫舍
- 动态规划 思路没有理清楚,复习
- 200 岛屿数量
- 递归标记,不用回溯
- 206 反转链表
- 定义一个pre便于操作
- 207 课程表
- 先看210,构建拓扑结构,利用深度优先或广度优先构建
- 208 实现 Trie (前缀树)
- 看答案,复习
- 215 数组中的第K个最大元素
- 快排方式:O(n)
- 最小堆:O(nlogk)
- 221 最大正方形
- 动态规划
- 226 翻转二叉树
- 递归和先序遍历和后续遍历一样
- 234 回文链表
- 快慢指针找到中点,后半部分反转,前后对比
- 236 二叉树的最近公共祖先
- 递归,不熟悉,复习
- 238 除自身以外数组的乘积
- 左右乘积,不熟悉,复习
- 239 滑动窗口最大值
- 最大堆, 用pair处理索引的问题
- 单调队列,不熟悉,复习
- 分块+预处理,待学习实践
- 240 搜索二维矩阵 II
- z字形,巧妙,复习
- 279 完全平方数
- 动态规划,不要用递归
- 283 移动零
- 双指针更直观,但是自己的时间开销似乎更小,可能是双指针的swap次数太多,且swap是三次赋值且有临时变量
- 287 寻找重复数
- 快慢指针,巧妙,注意理解,从0开始,而0不参与,只有有指向自己或重复指向则存在环,则这个点是重复的元素,复习
- 297 二叉树的序列化与反序列化
- 考察递归思想,复习
- 300 最长递增子序列
- 动态规划: O(n*n)
- 贪心+二分查找: O(nlogn), 有难度,不太理解,复习
- 309 最佳买卖股票时机含冷冻期
- 动态规划
- 312 戳气球
- 区间型动态规划, 不熟悉,复习
- 322 零钱兑换
- 动态规划
- 337 打家劫舍 III
- 动态规划,状态的定义可以有效的简化问题
- 338 比特位计数
- 关于二进制的计算不是很熟悉,需要多练习,复习
- 最高有效位和最低有效位,巧妙
- 394 字符串解码
- self 递归
- 399 除法求值
- 注意递推关系的推导和find函数内部各操作的执行顺序,复习
- 406 根据身高重建队列
- 从大到小考虑,更容易理解,先排序,复习
- 416 分割等和子集
- 先将问题简化为一个动态规划问题,同494
- 动态规划,不熟悉,复习
- 437 路径总和 III
- 前缀和,复习
- 注意int求和可能越界,要用long
- 438 找到字符串中所有字母异位词
- 对即将发生变化的情况处理,简洁巧妙,复习
- 448 找到所有数组中消失的数字
- 原地修改,取模找到原来的数,巧妙,复习
- 461 汉明距离
- 二进制相关操作,复习
- 494 目标和
- 先将问题简化为一个动态规划问题,同416
- 将问题简化为动态规划问题不会,复习
- 538 把二叉搜索树转换为累加树
- 递归还是不熟,复习
- 方法2待学习
- 543 二叉树的直径
- 结合538理解递归,复习
- 560 和为 K 的子数组
- 注意k可以为负数,所以用不了滑动窗口
- 581 最短无序连续子数组
- 理解有难度,复习
- 617 合并二叉树
- 递归
- 621 任务调度器
- 看答案,复习
- 方法二待学习
- 647 回文子串
- 中心扩展
- 方法2带学习
hot 100(add)
1 | class Solution { |
11
15
17
19
20
21
22 括号生成
23
31 下一个排列
- 策略:要变大,且变为大的中最小的
- 变大,则得在后面元素中找到比当前元素大的元素
- 变为大的中最小的则当前元素尽可能靠右
- 策略:要变大,且变为大的中最小的
32 最长有效括号
- 巧妙,待复习,看解析
- 栈方法和非栈方法都很巧妙
33 搜索旋转排序数组
- 二分,待优化,代码不简洁
-
- 学习如何二分查找找到第一个大于等于target的位置,第一个大于target的位置
39
42 接雨水
- 不会,看解析,先理解动态规划,再理解双指针
- 复习复习复习
46
48 旋转图像
- 巧妙,记忆
49
53 最大子数组和
- 不会,看解析,动态规划不会
55 跳跃游戏
- 贪心,看代码更易理解
56 合并区间
62
64
70
72 编辑距离
- 初始化放在外面单独处理性能更好
- min时用临时变量记录比每次使用f[i][j]性能更好
1 | class Solution { |
剑指offer(专项突破)
1 | 输入范围[−2^31, 2^31−1] |
- 002 二进制加法
- 注意使用reverse函数,可以简化问题
- 003 前 n 个数字二进制中 1 的个数
- 动态规划,最低位
- 004 只出现一次的数字
- 从方法2开始理解,巧妙,记忆,但这种方式感觉没有锻炼意义
- 还是用哈希表,常规方法
- 005 单词长度的最大乘积
- 位掩码
- 利用位掩码计算两个字符串是否有公共字符,学习,复习
1 | // masks[i]记录第i个单词的位掩码 |
006 排序数组中两个数字之和
- 双指针,注意需要有序
007 数组中和为 0 的三个数
- 先排序,注意去重,内层用双指针
-
- 注意先加nums[r],再判断
009 乘积小于 K 的子数组
- 每次记录以nums[r]结尾满足条件的个数
- 易错复习
010 I 010. 和为 k 的子数组
- 前缀和+哈希, 复习
011 0 和 1 个数相同的子数组
- 方法同010
- 记录1-0的差值
012 左右两边子数组的和相等
013 二维子矩阵的和
- 二维前缀和
014 字符串中的变位词
- 滑动窗口
- 双指针,巧妙,复习
015 字符串中的所有变位词
- 同014
016 不含重复字符的最长子字符串
- 滑动窗口
- 官方方法更直观,学习,复习
017 含有所有字符的最短字符串
- 滑动窗口
- 用范围索引记录结果,而不是直接记录满足条件的字符串,少用substr,性能开销非常大,复习
018 有效的回文
- isalnum的使用
019 最多删除一个字符得到回文
- 递归
- 官方贪心,但思路很简单,不过需要把思路理清除,复习
020 回文子字符串的个数
021 删除链表的倒数第 n 个结点
- 双指针
022 链表中环的入口节点
- 2(a+b) = a + b + n(b + c)
023 两个链表的第一个重合节点
024 反转链表
025 链表中的两数相加
- 先反转再求和
026 重排链表
- 找中点+反转+归并
- 学习官方归并的方式:一次执行两步操作
027 回文链表
- 找中点+反转+比较
028 展平多级双向链表
- 递归
029 排序的循环链表
- 易出错
- 先找到升序的起始位置,然后按常规操作找到合适的位置
-
- 哈希表支持插入,删除 O(1)
- 数组支持随机访问 O(1)
050 向下的路径节点之和
- 易错,复习
053 二叉搜索树中的中序后继
- 不熟练,复习
056 二叉搜索树中两个节点之和
- 代码简化
057 值和下标之差都在给定的范围内
- 不会,看解析,复习
- 滑动窗口+哈希表: 越界问题,绝对值问题,lower_bound
- 桶: 学习
- 注意编号时负数的处理
058 日程表
- lower_bound, begin等迭代器使用,不熟悉,复习
- 线段树,学习
061 和最小的 k 个数对
- 不会,看解析
- 去重的巧妙性
065 最短的单词编码
- 用集合移除的方式效率更高
067 最大的异或
- 二进制问题,转化为字典树
- 字典树处理,看解析,第一个评论解析比官方更易理解
- 复习复习复习!!!
每日一题
- 1041 困于环中的机器人
- 模拟,考虑各种情况,总结每种情况的返回值,复习
- ++取模,–取模(–取模之前需要先加模长)
- 2409 统计共同度过的日子数
- 1157 子数组中占绝大多数的元素
- 不会,看解析
- 1026 节点与其祖先之间的最大差值
- 递归
- 优化:只有记录前面的最大值和最小值,看解析证明
- 1043 分隔数组以得到最大和
- 动态规划
- 问题的抽象不会,复习,,,
- 1187 使数组严格递增
- 最多可以替换的次数为 min(n,m) : 因为替换后是严格递增的,所以v2中的数只能使用一次,如果使用2次则v1中的就必定存在两个相同的数,则不严格递增了
- 不会,复习,锻炼思路
- 2413 最小偶倍数
- 最小公倍数,最大公因数
- 1105 填充书架
- 不会,复习,看解析:更好理解
- 2418 按身高排序
- 利用堆索引的思想
- 1163 按字典序排在最后的子串
- 不懂,看答案,复习
- 易理解的解答
- 1048 最长字符串链
- 1015 可被 K 整除的最小整数
- 数学: 取模,递推
- 优化:当 k 为 2 或者 5的倍数时,能够被 k 整除的数字末尾一定不为 1,所以此时一定无解
1 | // resid = 1 mod k |
- 2611 老鼠和奶酪
- 贪心+排序/优先队列
- 注意问题的转化,将问题转化为在n个数中选择k个数,使得和最大,也就是求n个中前k个大的数的和 巧妙!!!
题型
数组
-
- 双指针
-
- 双指针 同上
-
- 双指针 同上
-
- 双指针 注意范围
排序应用
-
- 计数排序
- 三路快排(适用于重复元素较多的情况)
- [0,lt] == 0 lt是闭区间 则lt初始=-1 如果初始lt=0 那么久默认0位置就是==0了
- [lt+1, i) == 1
- [gt, n-1] == 2 同理 gt是闭区间 所以gt初始=n
-
- 逆向双指针
-
- 三路快排
对撞指针
-
- 字符串操作 isalnum tolower
-
- 有难度
- 看解析
滑动窗口
定宽窗口和变宽窗口有区别
-
- 在有效时记录窗口宽度
-
- 不方便while滑动时 就一步一步的滑动
-
- 方法值得再研究
- 记录每个需要字符的状态 对状态改变时修改need
- 定宽滑动
-
- 变宽滑动
查找
set
map
-
- 经典(看的解析) 时间复杂度高
-
- 经典(看的解析) 时间复杂度高
16 最接近的三数之和
454. 四数相加 II (看的解析)
- 就是枚举 不要想复杂了
- 数学问题
-
- 数学问题
-
- 困难 优化点很多 多方考虑
- 键值:两个有范围的数 如何相加得到一个独一无二的数 计算之后的和分布在不同的区间
1 | x,y都是整数 |
查找表+滑动窗口
-
- Unordered_map
- 滑动窗口
-
- unordered_set
二分搜索树+滑动窗口
- 220. 存在重复元素 III
- 使用set 复习
- 桶排序比较复杂
| lower_bound | 返回指向首个不小于给定键的元素的迭代器 (公开成员函数) |
|---|---|
| upper_bound | 返回指向首个大于给定键的元素的迭代器 |
差分数组
注意对交点(增加和减少的汇聚点)的处理,根据业务情况确定在哪减
数学
- 每日一题:1015. 可被 K 整除的最小整数
- 重要等式: 证明
(a+b)%m = (a%m+b%m)%m(a*b)%m = ((a%m)*(b%m))%m
- 重要等式: 证明
- 快速幂50. Pow(x, n)
1 | // 快速幂 |
1 | // 快速乘 |
- 29 两数相除
快速幂/快速乘: 下面的面试部分有讲解
最大公因数: gcd(n,m)
1 | // 辗转相除法 |
最小公倍数: clm(n,m)
1 | a = n/gcd(n,m); |
- offer专项 071 按权重生成随机数
- 就是在权重范围内生成随机数,随机数落在哪个区间,就返回那个区间对应的数
字符串
对字符串排序
两个字符串是否相等,直接用s == t判断, 比自己比较快
线段树
-
map + 二分查找,简洁,易懂
- 容器查找为空则结果等于begin,容器为空的情况下begin == end 不熟悉,复习
线段树
- lazy记录这个区间所有点都已预定 tree记录这个区间有至少一个点被预定过了
二进制
异或性质
- a^b = b^a
- x = a^b —-> a = x^b
- offer专项 067 最大的异或
- 字典树处理,看解析,第一个评论解析比官方更易理解
- 复习 容易忘
二分查找
offer专项 068 — 073
offer 专项 072 求平方根
- 学习这种写法,多场景可用,记录可能满足的情况(and = mid)
- 将可能满足条件的情况记录,另一种情况直接不满足条件,用l<=r退出,或l<r退出,根据具体情况而定
- 学习这种写法,多场景可用,记录可能满足的情况(and = mid)
1 | class Solution { |
- LCR 073. 爱吃香蕉的狒狒
- 时间复杂度O(nlogk)
栈、队列
1 | vector<string> split(const string& s, char k) { |
递归
- 144 二叉树的前序遍历
- 94 二叉树的中序遍历
- 145 二叉树的后序遍历
- 341 扁平化嵌套列表迭代器
- 递归先展开
队列
- 102 二叉树的层序遍历
- 不记录层数的解决方案
- 107 二叉树的层序遍历 II
- 103 二叉树的锯齿形层序遍历
- 双队列
- 199 二叉树的右视图
BFS最短路径
- 279 完全平方数
- 因为是需要最少的平方数,所以就是最短路径,所以BFS效果好
- BFS倒着入队效果可能更好(最大的平方数先入队,例如对于15,第一层入队顺序:6(15-9), 11(15-4),14(15-1))
- 数学方法效果最好 记忆结论
- 动态规划 待学习, 已学习,效果不如BFS,因为对于全是1的情况的都考虑了,换成递归的形式深度会很大,所以效果不如BFS
- BFS 去重的理解(对于相同值,前面入队过的值至少深度是小于等于当前值的,所以当前值继续只会大于等于前面的值,所以可以不入队)
- 因为是需要最少的平方数,所以就是最短路径,所以BFS效果好
- 127单词接龙
- 巧妙构建树
- 双向BFS的思想
- 126 单词接龙 II
- 回溯 待学习
优先队列
- 347 前 K 个高频元素
- 快排方式更快
- 23. 合并 K 个升序链表
- 分治合并 待学习
- 优先队列
链表
1 快慢指针定位链表中点时,前面添加dummy,这样定位就正好在中间了
-1 0 1 2 3 4 5 n = 6 中间位置:2
-1 0 1 2 3 4 5 6 n = 7 中间位置:3
2 不方便while的就直接用for确定移动的次数,这样不容易出错
3 充分利用滑动的指针:148 自底向上的cur的使用,复习
offer专项 021 删除链表的倒数第 n 个结点
- 双指针,只遍历一遍,前后指针差为n,巧妙,记忆
2 两数相加
- 不使用原链表,返回链表不算空间
-
- 链表翻转则和2一样
- 链表不翻转,使用栈(要额外的空间)
21 合并两个有序链表
- 类比数组归并,小的压入数组,就相当p->next = 小的
23 合并 K 个升序链表
- 熟悉优先队列的使用,复习
114 二叉树展开为链表
- 递归思想,复习
- 压栈,复习
141 环形链表
- 快慢指针
142 环形链表 II
146 LRU 缓存
148 排序链表
- 自顶向下好写
- 自底向上复杂,复习
206 反转链表
92 反转链表II 有难度
- 只遍历一遍如何实现
- 翻转不要抽离出去,直接就地翻转
- 只遍历一遍如何实现
25 K 个一组翻转链表 困难
- 也不是很难,关键在于定位要翻转的范围
234 回文链表
- 找中心点,反转,比对,每个步骤都分开做,因为合在一起太复杂,容易错
offer 专项077 链表排序
- 148
- 归并排序,复习复习复习!!! 考察归并和链表
-
- 删除所有重复的元素,使每个元素只出现一次
-
- 删除原始链表中所有重复数字的节点,只留下不同的数字
- 86. 分隔链表
- 借用92中一次遍历的思想
- 官方解法: 维护两个链表也很简便
- 328. 奇偶链表
- 借用86中维护两个链表的思想
- 具体实现方式略有不同
- 203. 移除链表元素
- 24. 两两交换链表中的节点
- 143 重排链表
- 考察点多 重做复习
- 快慢指针找中点
- 链表翻转
- 链表合并
- 147. 对链表进行插入排序
- 模拟插入排序
- 满足升序 直接往后走
- 不满足则该节点需要前移
- 237 删除单链表节点
- 61 旋转链表
- 官方解法更好
常见记录
1 | // 反转链表 |
树
通过空节点判断递归到底,判断更简洁
1 | if(!root1 && !root2){ |
- 94 二叉树的中序遍历
- 非递归,复习
- 96 不同的二叉搜索树
- 不会,复习!!!
- 动态规划,巧妙
- 98 验证二叉搜索树
- 中序遍历
- 递归,向下传递范围,复习
- 101 对称二叉树
- 递归,控制传入的对称关系,复习
- 102 二叉树的层序遍历
- 利用q.size()
- 104 二叉树的最大深度
- 105 从前序与中序遍历序列构造二叉树
- 114 二叉树展开为链表
- 递归思想
- 124 二叉树中的最大路径和
- 递归思想
- 226 翻转二叉树
- 递归思想
- 236 二叉树的最近公共祖先
- 递归思想
- 297 二叉树的序列化与反序列化
- 递归思想
- 序列化,通过叶子节点的左右子树为空来判断递归到底
- 字符串转数字:stoi、atoi 负数也可以转换
- 数字转字符串:to_string
- 注意可以传引用的尽量传引用,字符串传值和传引用性能差距10倍
- 337 打家劫舍 III
- 递归思想
- 通过空节点判断递归到底,更简洁
- 437 路径总和 III
- 递归思想
- 前缀和
- unordered_map中不使用的元素实时移除,性能更高
- 注意溢出
- 查看答案 待复习
- 方法1:巧妙 递归的嵌套
- 方法2:前缀和 注意:利用进入递归更新,推出递归还原
- 注意考虑是否有负数
- 538 把二叉搜索树转换为累加树
- 递归思想
- 利用全局变量
- 543 二叉树的直径
- 递归思想
- 617 合并二叉树
- 递归思想
- 判断优化
- 111 二叉树的最小深度
- 100 相同的树
- 222 完全二叉树的节点个数
- 利用编号的巧妙性进行位运算 有难度待复习
- 二分搜索
- 复习 理解位运算
- 110 平衡二叉树
- 112 路径总和
- 404 左叶子之和
- 257 二叉树的所有路径
- 113 路径总和 II
- 129 求根节点到叶节点数字之和
- 235 二叉搜索树的最近公共祖先
- 注意是:二叉搜索树,是有大小关系的
- 450 删除二叉搜索树中的节点
- 递归
- 重要 复习 迭代 理解指针
- 108 将有序数组转换为二叉搜索树
- 230 二叉搜索树中第K小的元素
- 进阶 红黑树
- 重要 复习 迭代中序遍历
单调栈
栈存储索引,通过索引取值,就不用存键值对,空间开销更小
在一维数组中对每一个数找到第一个比自己小/大的元素。这类“在一维数组中找第一个满足某种条件的数”的场景就是典型的单调栈应用场景
- 找到右边第一个比自己小的值
- 往右走
- cur比栈顶大则入栈
- cur比栈顶小则while(cur比栈顶小)出栈,直到比栈顶大则继续入栈
- 出栈元素右边第一个比自己小的元素就是cur, 进行记录
- 技巧: cur左边第一个比自己大元素就是cur可以入栈时,栈顶的元素 (典型案例:84)
典型案例:84
739 每日温度
- 栈存储index值,通过 t[st[i]]拿到值
84 柱状图中最大的矩形
- 找到左边第一个比当前元素小的,找到右边第一个比当前元素小的
- 注意初始化
85 最大矩形
- 需要依赖84才能做出来,没有84的基础基本做不了
581 最短无序连续子数组
- 感觉和单调栈没啥关系
- 双指针,模拟正常思考过程
- 往右走,则需要一直递增,若不满足则记录该位置,该位置是需要往左移动的,往右走完,记录的就是最右需要往左移的位置
- 往左走,则需要一直低价,若满足,,,
42 接雨水
- 动态规划易理解 推荐
- 双指针的策略没有理解透彻,复习,对动态规划的优化,不易理解
- 单调栈不简洁,不易理解
回溯
1 先排序有利于解决问题 有重复元素则排序
2 对于重复的元素,采用标记的方式,相同的元素只有在前面的元素使用后后面的元素才能使用,保证排列组合不会重复
3 尽可能在原数组上标记,不用额外开空间,节省了空间,性能也更好
- 17 电话号码的字母组合
- 22 括号生成
- 不熟练,复习,,,,
- 每次有两个选择,要么加入’(‘、要么加入’)’, 所以需要回溯保证,每层只加入一种
- 93 复原 IP 地址 重复做,考察细节
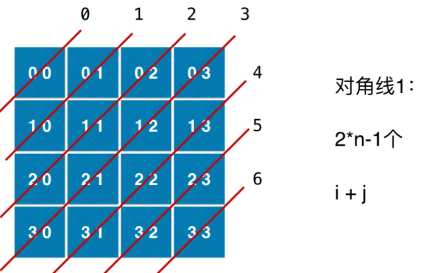
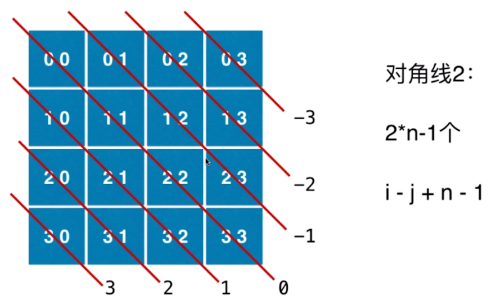
- 131分割回文串
- 回溯+动态规划 提前预处理所有可能的回文串 因为回溯过程中有重复计算
- 动态规划记录所有回文串 再学习
- 从对角线开始往两边扩展
- 初始化顺序,根据下一步要是的情况,决定这一步先初始化哪里
1 | // 动态规划记录所有回文串 |
排列组合
先排序有利于解决问题
对于重复的元素,采用标记的方式,相同的元素只有在前面的元素使用后后面的元素才能使用,保证排列组合不会重复
全排列
46 全排列
- 动态维护数组的方式 巧妙 学习
47 全排列 II
- 注意去重的方法 复习
- 有重复元素且每个元素只能使用一次
- 解决方案: 排序,标记使用过的,相同的元素,只有前面一个使用过了后面的才能使用
组合
二维平面的回溯
使用偏移量数组简化代码量,但可能影响性能,多了判断
- 79 单词搜索
- 在原数组上进行标记,不用额外开空间,节省了空间
floodfill
200 岛屿数量
- 原数组标记
130 被围绕的区域
- 原数组标记
- 位移判断优化和代码简化优化
- 代码简化会导致压栈太多,可能导致性能不如原始版本
417 太平洋大西洋水流问题
- 1 参考答案,待复习
- 2 参考答案内存开销更小
n皇后问题
- 51 N 皇后
- 看解析 看视频讲解8-8 待复习
- 下图的方式标记斜线是否可以放置,也可以用二进制数来标记(巧妙)
- 二进制部分没懂 待学习
- 52 N皇后2
- 37 解数独
- 参考官方解答,对于3*3块的记录
- 位运算优化待学习
301 删除无效的括号
- 困难,待做
- 广度优先,最短,最少就用广度优先
- 不会不会不会
494 目标和
offer专项081- 087
- 有重复元素则排序,并保证和前一个元素不同,如果和前一个元素相同则continue
- 无重复元素全排列可以用swap
- 有重复元素全排需要使用标记,不能用swap, 因为swap后会乱序,导致不能判断和前一个元素是否相同
- 排序
- 保证和前一个元素不同
- 标记
offer专项085. 生成匹配的括号
- 不熟悉,复习
广度深度优先
在递归开始或者在进入递归前进行标记,这样不容易出错
构建图:
- 字符串等情况,先将字符串映射为数字,便于使用vector存储图结构
广度优先:一般用于计算最短路径的场景题
106 二分图
- 不熟悉,复习
- 用序号来标记两个分组
107 矩阵中的距离
- 动态规划和广度优先 复习 不熟悉
- 动态规划
- 从某个0到某个1的距离计算,先向下再向右和先向右再向下是等价的
- 广度优先
- 关键点是每次只扩展一步,且对已经扩展的进行标记
108 单词演变
- 不会, 复习
- 图的构建不熟悉,复习
- 遍历记得标记已经遍历的元素
- 广度优先,找最短路径,记录层数的方法
111 计算除法
- 构建图,不熟悉,复习
- 广度优先,记录路径
动态规划
- 42 接雨水
offer专项 088-105
092 翻转字符
- 复习,记录状态简化问题
093 最长斐波那契数列
- 复习,不会
094 最少回文分割
- 分两步
- 预处理任意两点区间内是否是回文串,复习复习复习,巧妙解法
- 常规动态规划
- 分两步
096 字符串交织
- 不会,复习
097 子序列的数目
- 不会,复习
贪心
- 455. 分发饼干
- 392. 判断子序列
- 435. 无重叠区间
- 类似 动态规划中求最长递增子序列 300 (O(n^2))
- 此题用动态规划 不通过 运行时间过长
- 贪心思路 (O(n))
- 注意:每次选择中,每个区间的结尾很重要
- 结尾越小,留给了后面越大的空间,
- 后面越有可能容纳更多区间
- 按照区间的结尾排序,
- 每次选择结尾最早的,且和前一个区间不重叠的区间
1 | // 按照区间的结尾排序, |
牛客面经
情况2:一个链表有环,一个链表无环,这种情况不可能相交 相交后共用 一个有环 另一个一定也有 可以相交在环之前 也可以相交在换上
两个链表相交,且两个链表的入环节点是同一个(loop1 = loop2,就认为 loop1 和 loop2 是终止节点,问题就变成了两个无环链表找第一个相交节点) loop1 = loop2表示入环点相同 就可以确定是情况2了,,,
重要思想:如果两个单链表有共同的节点,那么从第一个共同节点开始,后面的节点都会重叠,直到链表结束。
因为两个链表中有一个共同节点,则这个节点里的指针域指向的下一个节点地址一样,所以下一个节点也会相交,依次类推
- 怎么判断链表相交
- 怎么判断链表有环
- 怎么找到环入口地址?为什么这么找?怎么证明
- 怎么判断两个有环链表是否相交?
求链表的中间结点
在二叉树中找路径最长的两个点
- dfs, 并维护一个长度为2的队列,每次递归到底,深度更深则将该点加入队首,并判断队列长度是否大于2,若大于则删除队尾
拼多多 3.12
多多君最近在研疗一种编码期法、对于连境出机的字花,用变的长提来改元,发提这样可以有
PS
前缀和+哈希表
位掩码,字符串求交
双指针,有序
滑动窗口,用左右索引记录范围(offer 017 专项)
快慢指针
- 快慢指针定位链表中点时,前面添加dummy,这样定位就正好在中间了
性能
- 注意可以传引用的尽量传引用,字符串传值和传引用性能差距10倍
- unordered_map中不使用的元素实时移除,性能更高
- 多级索引查询,用临时变量存储, 性能快一倍
1 | for(int i = 1; i <=n; ++i){ |
- 移除字符串中一个元素 code: 1048
- 用substr拼接比erase快一倍,内存消耗也更小,内存消耗大,可能是函数调用
1 | // substr拼接 |
- 存储26个字符
- 用vector存储比用unordered_map效率高,开销小
1 | vector<int> mp(26); |
- 直接操作字符串各位效率更高
1 | // s : hh:mm 24小时时间格式,返回分钟数 |
函数
- isalnum函数用于判断字符是否为字母(a-z和A-Z)或数字(0-9)
- reverse
- 字符串转数字:stoi、atoi 负数也可以转换 前缀0会剔除
- 数字转字符串:to_string
- unique + erase 数组去重: c++ unique函数
- upper_bound(起始迭代器,结束迭代器,比较值a) :返回严格大于a的元素的迭代器
- lower_bound : 指向首个不小于
key的元素的迭代器。若找不到这种元素,则返回尾后迭代器 - iota() 升序填充值
1 |
|
- accumulate
- 类似js中reduce
- memset
void *memset(void *s, int c, size_t n);- s指向要填充的内存块。
- c是要被设置的值。
- n是要被设置该值的字符数。
- 返回类型是一个指向存储区s的指针。
- reverse
- 复杂度:恰好交换
(last - first)/2次
1 | int a[] = {4, 5, 6, 7}; |
- find
1 | std::vector<int> v{0, 1, 2, 3, 4}; |
- sort
1 |
|
- C++中的__builtin_popcount()
https://blog.csdn.net/weixin_44915226/article/details/105367005
1 | 该函数是C++自带的库函数,内部实现是用查表实现的。 |
- tie()
- 解包,类似js中的解构
https://blog.csdn.net/lllzzzhhh2589/article/details/121584299
1 | struct S { |
- 向上向下四舍五入取整(以下只针对浮点数的运算)
1 | // 向上 |
- 整数向上取整
1 | // 1 |
常用
STL
stack、vector、list、queue常用方法
stack
top
push
pop
priority_queue
top
push
pop
queue
- front
- back
- push
- pop
vector
- front
- back
- push_back
- pop_back
- erase
- shrink_to_fit
deque
- front
- back
- push_front
- pop_front
- push_back
- pop_back
- erase
- shrink_to_fit
list
- front
- back
- push_front
- pop_front
- push_back
- pop_back
- erase
priority_queue
- 默认是最大堆
- 改为最小堆
1 | priority_queue<int, vector<int>, greater<int>> |
- 自定义比较函数
1 | // 个位数大的在前 |
二分查找
| lower_bound | 返回指向首个不小于给定键的元素的迭代器 (公开成员函数) |
|---|---|
| upper_bound | 返回指向首个大于给定键的元素的迭代器 |
注意点
容器为空的情况下可以调用 mp.count(key)
容器为空的情况下查找返回的迭代器为 mp.end() , 而容器为空的情况下mp.begin() == mp.end()
1 | unordered_map<vector<int>, int> mp; // 报错 |
输入输出
数据对
- 没有对数,没有结束标志
1 | 输入包括两个正整数a,b(1 <= a, b <= 1000),输入数据包括多组。 |
- 有结束标志
1 | 输入包括两个正整数a,b(1 <= a, b <= 10^9),输入数据有多组, 如果输入为0 0则结束输入 |
多行数据
- 有结束标志
1 | 输入数据包括多组。 |
- 有行数
1 | 输入的第一行包括一个正整数t(1 <= t <= 100), 表示数据组数。 |
- 没有行数,没有结束标志
1 | 输入数据有多组, 每行表示一组输入数据。 |
- 没有每行数据个数,没有行数,没有结束标志
1 | 输入数据有多组, 每行表示一组输入数据。 |
多个字符串
- 给定个数
1 | 输入有两行,第一行n |
- 多行字符串
1 | 多个测试用例,每个测试用例一行。 |
- 多行字符串,每个字符串用逗号隔开
1 | 多个测试用例,每个测试用例一行。 |
字符串
1 | INT_MAX = 2^31-1; |
字符串转int
atoi()和stoi()
- atoi()和stoi()函数都是只转换字符串的数字部分,如果遇到其它字符的话则停止转换
- 只返回有效数字 0123返回123
相同点
都是C++的字符处理函数,把数字字符串转换成int输出
头文件都是
#include<cstring>
不同点
<1>参数类型不同
atoi()的参数是const char*,因此对于一个字符串str我们必须调用c_str()的方法把这个string转换成const char*类型。stoi()的参数是const string&,不需要转化为const char*
<2>范围检查
atoi()不会做范围检查,如果超出范围的话,超出上界,则输出上界,超出下界,则输出下界;stoi()会做范围检查,默认范围是在int的范围内的,如果超出范围的话则会吐核超出范围。

string转char
c_str()
1 |
|
int转string
to_string()
大小写字符转换
1 |
|
判断字符数字
- isalnum函数用于判断字符是否为字母(a-z和A-Z)或数字(0-9)
isalnum
1 |
string移除最后一个元素
1 | string s = "string!"; |
string追加char
1 | string s = "abc"; |
位运算
https://blog.csdn.net/m0_64183293/article/details/122519405
GCC自带的一些builtin内建函数 :https://blog.csdn.net/tjcwt2011/article/details/118154919
- C++中的__builtin_popcount()
https://blog.csdn.net/weixin_44915226/article/details/105367005
1 | 该函数是C++自带的库函数,内部实现是用查表实现的。 |
- __builtin_ctz
- 这个函数作用是返回输入数二进制表示从最低位开始(右起)的连续的0的个数;如果传入0则行为未定义
二进制1个数
1 | 1 __builtin_popcount |
位与位异或位或
1 | 位与 & 0&0=0; 0&1=0; 1&0=0; 1&1=1; |
1 | Brian Kernighan 算法的原理是:对于任意整数x, 令 x = x & (x-1) 该运算将 x 的二进制表示的最后一个 1 变成 0 |
数值
1 | 1e9+7 // 10^9+7 一个比较大的质数 |
取绝对值
abs()
使用最大最小值
1 | <limits.h> |
保留小数点后n位**
- setprecision(n) : 表示保留n位,整体保留的位数
- fixed: 表示以小数点后开始记保留的位数
1 |
|