L247 - 快速搞定前端技术一面 匹配大厂面试要求
一、HTML
如何理解HTML语义化?
默认情况下,哪些HTML标签是块级元素、哪些是内联元素?
二、CSS
2.1布局
盒子模型的宽度如何计算?
- offsetWidth=(内容宽度+内边距+边框),无外边距
1 | div{ |
使offsetWidth === 设置的宽度,内边距和边框不占元素宽高,内容宽度会被压缩
box-sizing:border-box;
1 | div{ |
margin 纵向重叠的问题
相邻元素的margin-top和margin-bottom 会发生重叠
空白内容的标签也会重叠
相邻元素之间的margin距离以最大的那个margin为准
- 若中间有空白内容标签,则比较空白标签margin-top、空白标签margin-bottom、上方元素margin-bottom、下方元素margin-top, 哪个值大则为上方元素与下方元素之间的距离
1 |
|
margin负值的问题
- margin-top 和margin-left负值,元素向上、向左移动,会影响其他元素
- margin-right负值,右侧元素左移,自身不受影响
- margin-bottom负值,下方元素上移,自身不受影响
BFC理解和应用
- 什么是BFC
- Block format context ,块级格式化上下文
- 一块独立渲染区域,内部元素的渲染不会影响边界以外的元素
- 形成 BFC的常见条件
- float 不是none
- position是absolute或 fixed
- overflow不是visible
- display是flex inline-block 等
float布局的问题,以及clearfix(手写)
- 如何实现圣杯布局和双飞翼布局
- 圣杯布局和双飞翼布局的目的
- 三栏布局,中间一栏最先加载和渲染(内容最重要)
- 两侧内容固定,中间内容随着宽度自适应
- —般用于PC网页
- clearfix 清除浮动
flex画色子
- 实现一个三点色子
- flex主要属性
- align-self(交叉轴子元素)
- justify-content(主轴)
- align-items(交叉轴)
- flex-direction(方向,水平:row)
定位
absolute和relative分别依据什么定位?
- absolute: 依据最近一层的定位元素定位(absolute, fixed,relative,body)
- relative: 相对自己
居中对齐有哪些实现方式?
水平居中
- inline元素:
text-align: center- inline元素的父元素中设置
text-align: center - 定义
text-align: center属性的子标签会继承这个属性
- inline元素的父元素中设置
- block元素:
margin:auto- block元素自身设置
margin:auto - block元素自身设置
text-align: center可以使其内部的文字水平居中
- block元素自身设置
- absolute元素:left: 50% + margin-left负值
- 父元素为定位元素(absolute, fixed,relative,body)
- absolute元素自身设置
left:50%; margin-left:-absolute元素自身宽的一半left:50%是右移父元素宽的一半,即absolute元素右边移动到父元素的中轴margin-left:-absolute元素自身宽的一半是利用margin负值使自身左移
- inline元素:
垂直居中
inline元素:line-height的值等于height值
- 父元素中设置line-height的值等于height值
block元素内容
- 设置block元素中的文字垂直居中:设置自身line-height的值等于height值
absolute元素: top:50% + margin-top 负值
- 父元素为定位元素(absolute, fixed,relative,body)
- absolute元素自身设置
top:50%; margin-top:-absolute元素自身高的一半top:50%是右移父元素高的一半,即absolute元素上边移动到父元素的中轴margin-top:-absolute元素自身宽的一半是利用margin负值使自身上移
absolute元素: transform(-50%,-50%)
- 次方法兼容性差
- 此方法不用计算自身元素的宽高的一半
position: absolute; 1
2
3left: 50%;//右移父元素宽的一半
top: 50%;//下移父元素高的一半
transform: translate(-50%, -50%)//自身左移上移自身的宽高的一半
- 此方法不用计算自身元素的宽高的一半
- 次方法兼容性差
absolute元素: top, left, bottom,right = 0 + margin: auto
1 | position: absolute; |
图文样式
line-height的继承问题
- 写具体数值,如30px,则继承该值
1 | body { |
- 写比例,如2、1.5,则继承该比例
1
2
3
4
5
6
7
8
9
10body {
font-size: 20px;
line-height: 2;
}
p {
background-color: #ccc;
font-size: 16px;
}
//p行高 16px*2 ,所以行高为32px
//此时是p继承了 line-height: 2; 然后计算出行高32px
- 写百分比,如200%,则继承计算出来的值(考点)
1 | body { |
响应式
rem是什么?
px,绝对长度单位,最常用,1px=2像素
em ,相对长度单位,相对于父元素,不常用
rem ,相对长度单位,相对于根元素,常用于响应式布局
1 | html { |
响应式布局的常见方案?
- 使用media媒体查询,再根据不同屏幕尺寸设置html的font-size,再利用rem实现响应式
网页视口尺寸
window.screen.height//屏幕高度window.innerHeight//网页视口高度- 屏幕减去页面上下导航的高度
document.body.clientHeight// body高度- body高度是根据内容变化的,内容越多高度就随之增加
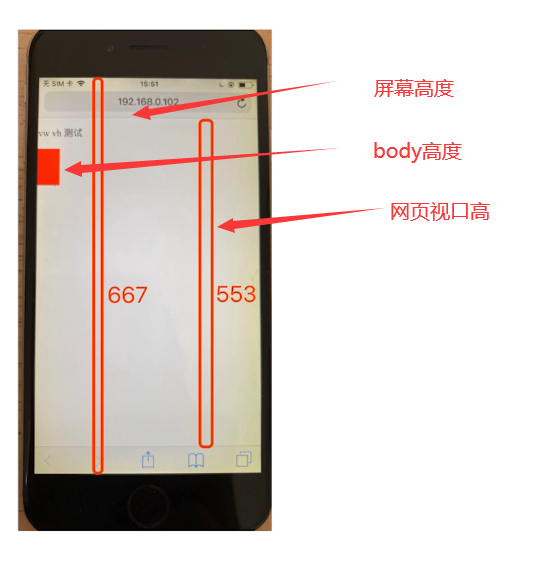
vh/vw
1vh = 网页视口高度的1/100
- window.innerHeight === 100vh
1vw = 网页视口宽度的1/100
- window.innerWidth === 100vw
1vmax = max(1vh, 1vw) //谁大取谁
1vmin = min(1vh, 1vw) //谁小取谁
三、javascript
变量类型和计算
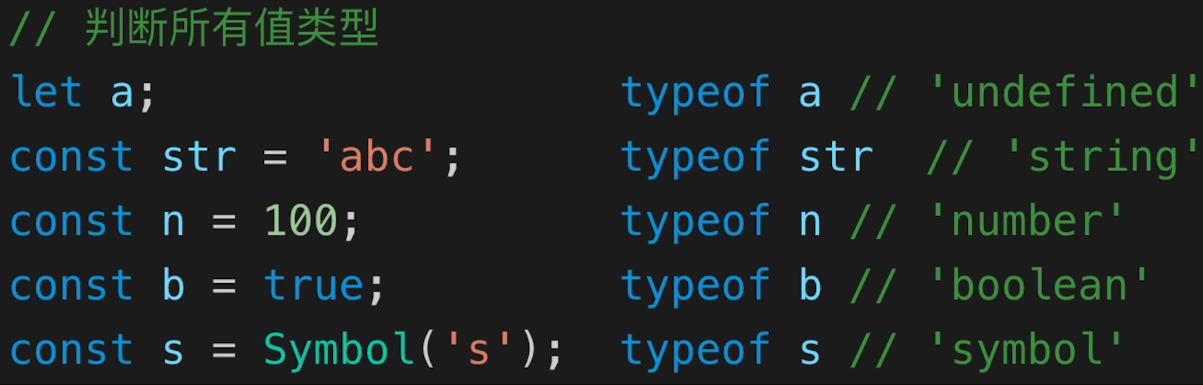
typeof 能判断哪些类型
识别所有值类型
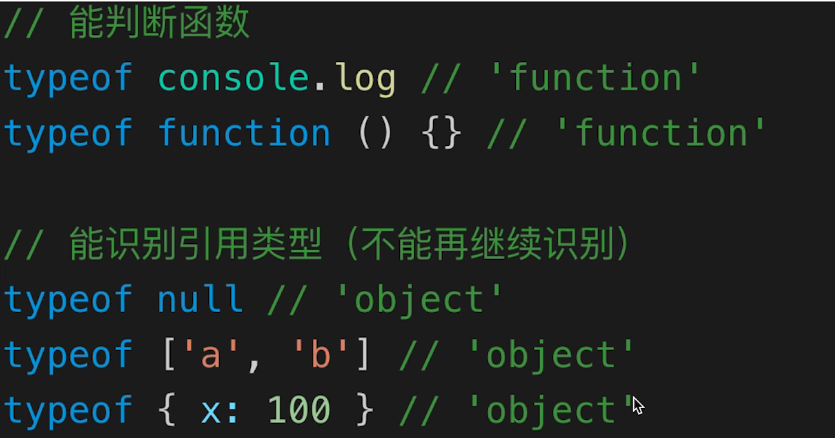
识别函数
判断是否是引用类型(不可再细分)
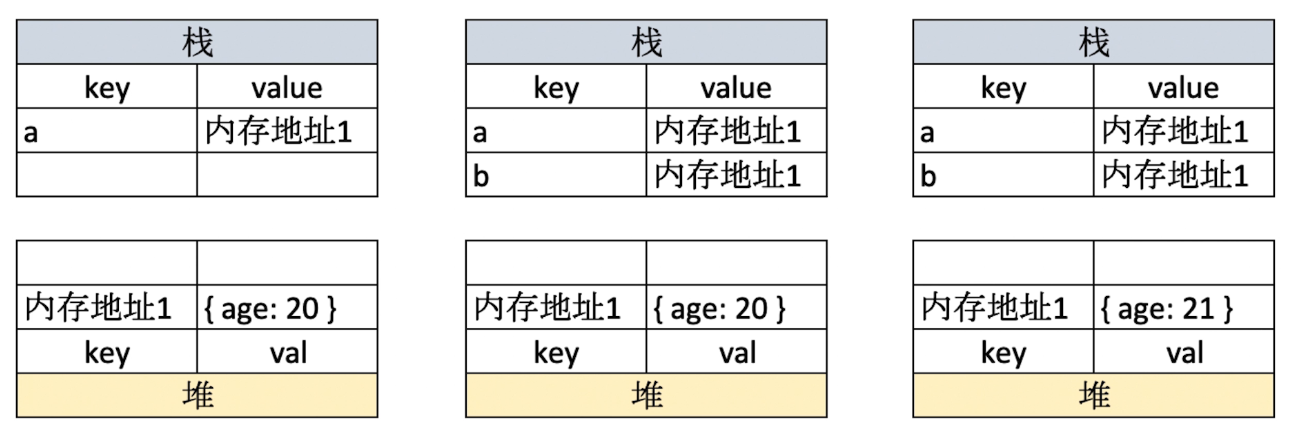
值类型和引用类型的区别
值类型
- 值类型是用栈存储的
1 | //值类型 |

引用类型
- 引用类型是同时用堆栈存储的,实际内容存在堆中,栈中只存储了内存地址,所以两个变量实际是指向同一个内存地址的
1 | //引用类型 |
- 常见值类型
let a: undefined类型- 字符串
- 数字
- 布尔
- es6中的symbol
- 常见引用类型
- 对象
- 数组
const n = null//特殊引用类型,指向空地址- 函数 //特殊引用类型 不存储数据
数据类型转换
字符串拼接
1 | const a = 100 + 10// 110 |
if语句和逻辑运算
- truly变量:
!!a === true的变量 - falsely变量:
!!a === false的变量
1 | //以下是falsely变量。除此之外都是truly变量 |
何时使用===何时使用==
- ==
100 == '100'true0 == ''true0 == falsetruefalse == ' 'truenull == undefinedtrue
结论:
1 | //除了== null 之外,其他都一律用===,例如 |
手写深拷贝
函数可以深拷贝吗????
1 | /** |
原型和原型链
如何准确判断一个变量是不是数组 ?
a instanceof Array
手写一个简易的jQuery , 考虑插件和扩展性
- 插件即在显示原型上添加属性:
a.prototype.x = mmmm - 扩展性即在继承
class的原型本质,怎么理解?
- 原型及原型链的理解
作用域和闭包
apply,call,bind
https://blog.csdn.net/a15180180753/article/details/103495023
this的不同应用场景,如何取值?
- 当做普通函数被调用
- 使用call apply bind
- 作为对象方法调用
- 在class的方法中调用
- 箭头函数
手写bind函数
实际开发中闭包的应用场景,举例说明
- 事件函数的封装
- 隐藏数据
- 用闭包模拟私有方法
- dom生成10个标签,点击第几个标签就弹出数字几
作用域
全局作用域
- 全局定义
函数作用域
- 函数体内定义
块级作用域(ES6新增)
- if、while、for的
{ }块中定义
- if、while、for的
1 | if(true){ |
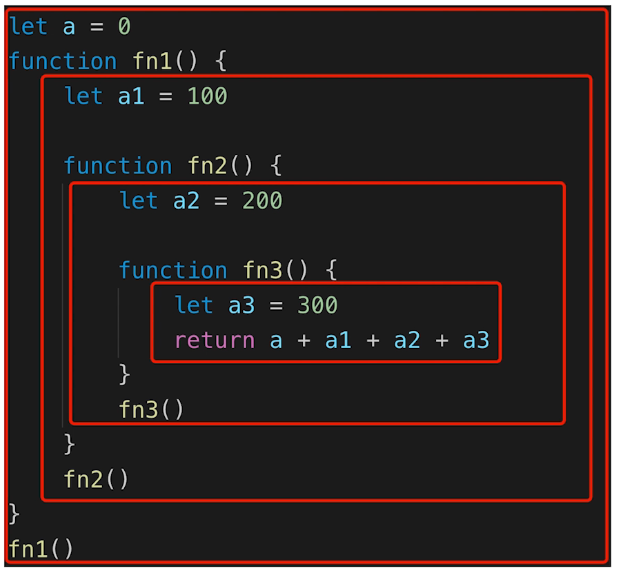
自由变量
- 自由变量定义:一个变量在当前作用域没有定义,但被使用了
- 向上级作用域,一层一层依次寻找,直至找到为止
- 如果到全局作用域都没找到,则报错xx is not defined
闭包
闭包就是能够读取其他函数内部变量的函数
作用域应用的特殊情况,有两种表现:
- 函数作为参数被传递
- 函数作为返回值被返回
1 | //函数作为返回值 |
1 | // 函数作为参数被传递 |
总结:
- 所有的自由变量的查找,是在函数定义的地方,向上级作用域查找
- 不是在执行的地方查找!!!
this
this取什么值是在函数执行的时候确定的,不是在定义时确定的
情况1:
.call()函数会改变this指向,并且函数直接执行.bind()函数会改变this指向,并且需要接受返回的函数,然后再执行
1 | function fn1() { |
情况2:定时器
- 定时器的回调函数中的this不再指向对象,而是指向window
- 因为定时器的回调函数是挂在浏览器上执行的,所以this指向浏览器即window
- 函数内的this指向调用该函数的对象
1 | const zhangsan = { |
情况3:箭头函数
- 箭头函数的this取上级作用域的this
1 | const wangwu = { |
情况4:对象
- 对象中方法this指向对象本身
1 | class People { |
apply,call,bind方法
apply,call,bind方法是函数原型上的方法:Function.prototype.apply,,,,,,
bind 是返回对应函数,便于稍后调用;apply 、call 则是立即调用 。
三者的相同点:都是用来改变this的指向
call()和apply()的区别:
相同点:都是调用一个对象的一个方法,用另一个对象替换当前对象(功能相同)
- B.call(A, args1,args2);即A对象调用B对象的方法
- F.apply(G, arguments);即G对象应用F对象的方法
不同点:参数书写方式不同
call()的第一个参数是this要指向的对象,后面传入的是参数列表,参数可以是任意类型,当第一个参数为null、undefined的时候,默认指向window;bind和call的传参方式是一样的
apply():第一个参数是this要指向的对象,第二个参数是数组
bind,call,apply的使用场景
call
判断数据类型
类数组转数组 (类数组是指具有索引和值的结构,也有length属性的对象,关键是类数组不是数组,是对象,不具有数组的方法)
1 | // * 判断数据类型 |
- apply
- 获取数组最大值
- 利用了apply传入的参数是数组,如果不用apply就要用
...展开符进行展开再传入
- 利用了apply传入的参数是数组,如果不用apply就要用
- 获取数组最大值
1 | // apply 对给定数组求最大值/最小值 |
- bind
- react类组件事件响应函数的绑定
1 | class App extends React.Component { |
手写bind
- arguments : Javascript中存在一种名为伪数组的对象结构。还有像调用 getElementsByTagName , document.childNodes 之类的,它们返回NodeList对象都属于伪数组。不能应用 Array下的 push , pop 等方法。
- 但是我们能通过 Array.prototype.slice.call 转换为真正的数组的带有 length 属性的对象,这样 domNodes 就可以应用 Array 下的所有方法了。
- arguments中存储着传给当前函数的所有参数
1 | // 模拟 bind |
闭包的应用
- 事件函数的封装
1 |
|
- 隐藏数据,缓存插件
1 | // 闭包隐藏数据,只提供 API |
- 用闭包模拟私有方法
1 | const makeCounter = function () { |
- dom生成10个标签,点击第几个标签就弹出数字几
1 | //正确方法 |
1 | // 注意var是函数作用域,所以在这里for的块没有形成闭包,需要用()(i)来形成闭包 |
异步和单线程
同步和异步的区别是什么?
手写用Promise加载一张图片
前端使用异步的场景有哪些?
setTimeout问题(js任务队列)
1 | //setTimeout笔试题 |
- 手写用Promise加载一张图片
1 | function loadImg(src) { |
请描述event loop (事件循环/事件轮询)的机制,可画图
- 自行回顾event loop的过程
- 和DOM渲染的关系
- 微任务和宏任务在event loop过程中的不同处理
什么是宏任务和微任务,两者有什么区别?
Promise有哪三种状态?如何变化?
- pending 状态,不会触发then和catch
- resolved状态,会触发后续的then回调函数,不会触发catch
- rejected状态,会触发后续的catch回调函数,不会触发then
场景题- promise then和catch的连接
1 | // 第一题 |
- 场景题- async/await语法
1 | async function fn( ) { |
1 | !( async function () { |
- 场景题- promise和setTimeout的顺序
1 | console.log ( 100) |
- 场景题–外加async/await的顺序问题
1 | async function async1 ( ) { |
async/await和Promise的关系
- 执行async函数,返回的是 Promise对象
- await相当于Promise 的then
- try…catch可捕获异常,代替了Promise的catch
宏任务有哪些?微任务有哪些?微任务触发时机更早
微任务、宏任务和DOM渲染的关系
微任务、宏任务和DOM渲染,在event loop 的过程
并行、并发、单线程
- 并行是指同时执行,只有多线程的语言才支持
- 并发本质是充分利用cpu资源(多个任务交替使用cpu),并没有正真同时执行
- JavaScript、Python都是单线程语言,只能实现并发,不能实现并行
- Python的多线性是通过伪线程实现的
- JavaScript 并发
- 宏任务,微任务机制实现并发,EventLoop
- 本质是CPU足够快,当请求资源时(查询数据库、网络请求等),此时CPU就空出来了,而这时CPU会切换到其他任务,只要切换的足够快,就实现了并发。
- Node.js 优势是只能异步编程,不支持同步编程,异步编程就大大提升了资源的利用率
- 浏览器和nodejs 已支持JS启动进程,即并发,如Web Worker
- JS和DOM渲染共用同一个线程,因为JS可修改DOM结构
同步和异步
异步是基于js单线程的
异步不会阻塞代码执行, 定时器函数
同步会阻塞代码执行,例如
alert()
应用场景
- 网络请求,如ajax图片加载
- 定时任务,如setTimeout
- 查询数据库
- 读写文件
- DOM事件
event loop
event loop(事件循环/事件轮询/任务队列)
- JS是单线程运行的
- 异步要基于回调来实现
- event loop就是异步回调的实现原理
- 异步和DOM事件都是使用回调,基于event loop
宏任务和微任务
宏任务macroTask和微任务microTask
宏任务: setTimeout , setInterval , Ajax,DOM事件 ; 宏任务是由浏览器规定的
微任务: Promise async/await; 微任务是ES6语法规定的
微任务执行时机比宏任务要早
1 | console.log(100) |
微任务和宏任务的区别
- 宏任务: DOM渲染后触发,如setTimeout
- ES 语法没有,JS 引擎不处理,浏览器(或 nodejs)干预处理,
- 即交给Web APIs处理,然后回调函数加入Callback Queue
- 微任务: DOM渲染前触发,如Promise
- ES 语法标准之内,JS 引擎来统一处理。
- 即微任务不交给Web APIs处理, 直接加入micro task queue, Call Stack 清空后直接在micro task queue中提取微任务的回调函数执行
1 | // 修改 DOM |
执行流程:
- 代码在Call Stack中执行,遇到同步代码则直接执行,遇到遇到微任务则加入micro task queue ,遇到宏任务则交给我Web APIs 处理,Web APIs处理完成后将回调函数加入宏任务队列(Callback Queue)
- 代码都执行完,Call Stack空闲后,从micro task queue 提取微任务的回调函数执行
- Call Stack再次空闲,且micro task queue也为空后,开始DOM渲染
- DOM渲染完后,触发Event Loop ,从宏任务队列提取回调函数执行
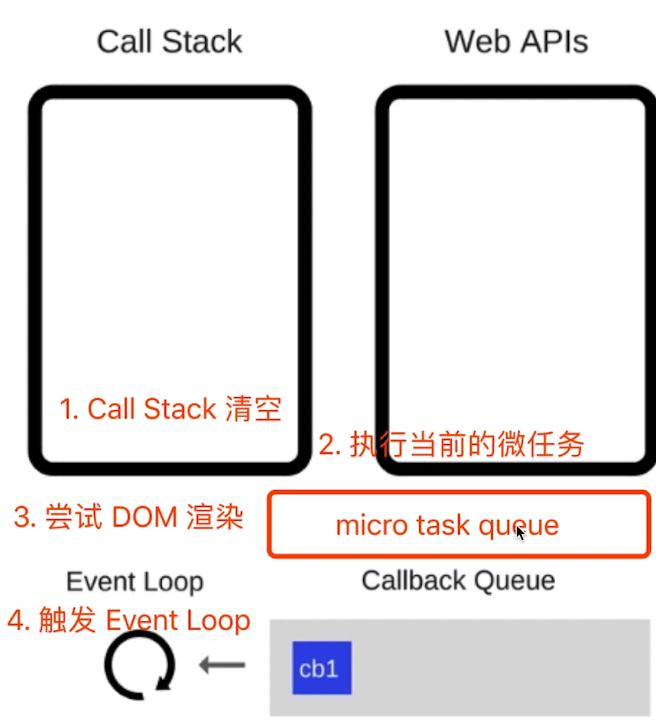
event loop和DOM渲染
每次Call Stack清空(即每次轮询结束) , 即同步任务执行完
都是DOM重新渲染的机会, DOM结构如有改变则重新渲染
然后再去触发下一-次 Event Loop
1 | const $p1 = $('<p>一段文字</p>') |
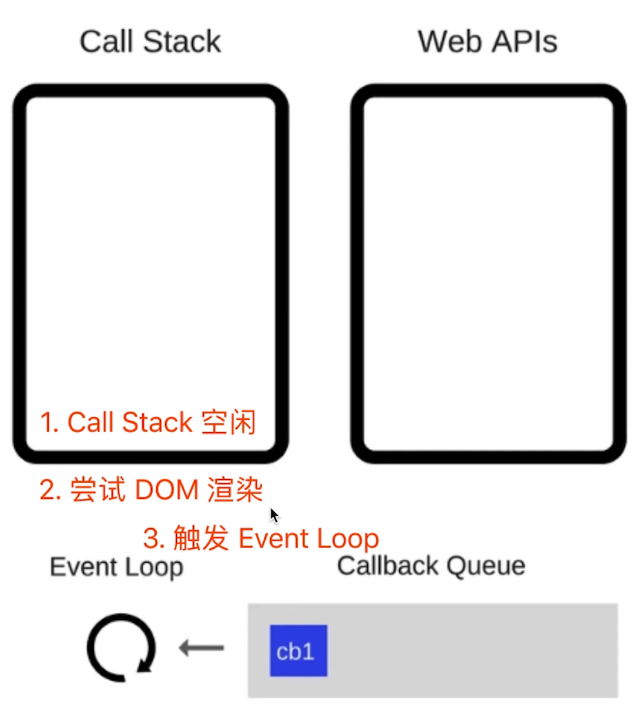
JS Web API
DOM
- DOM是哪种数据结构
- 树结构(DOM树)
- DOM操作的常用API
- attribute和property的区别
- 一次性插入多个DOM节点,考虑性能
property 和attribute区别
- property :修改对象属性,不会体现到 html结构中(修改的是model层的数据) ; 推荐
- attribute :修改html属性,会改变html结构(修改的view层的数据)
- 两者都有可能引起DOM重新渲染
1 | // property 形式 |
操作DOM节点
1 | // 以ID名获取元素 |
操作DOM结构
nodeType ===1 表示 元素为标签
nodeType ===3 表示 元素为text类型,即为标签的文本内容
1 | const div1 = document.getElementById('div1') |
DOM性能
- 频繁更新DOM会耗费很多资源,所以尽量减少刷新的次数,可以将更新的整理好后一次性更新
将频繁操作改成一次性操作
- 利用
document.createDocumentFragment()
1 | const list = document.getElementById('list') |
DOM查询做缓存
1 | //DOM查询做缓存 |
PS: 测试代码
1 |
|
BOM
navigator
1 | // navigator |
history
1 | // history |
screen
1 | // screen |
location
1 | //location |
事件
- 编写一个通用的事件监听函数
- 描述事件冒泡的流程
- 无限下拉的图片列表,如何监听每个图片的点击? 事件代理
事件绑定
- 阻止事件默认行为:
event.preventDefault(); 例如点击a标签时会阻止跳转
通用的事件绑定函数–简版
1 | // 通用的事件绑定函数--简版 |
通用的事件绑定函数–可选择事件代理
1 | //html结构 |
1 | // 通用的事件绑定函数--可选择事件代理 |
事件冒泡
- 事件向上冒泡时,回调函数event.target始终为实际点击的元素
- 阻止冒泡:
event.stopPropagation()
1 | //html结构 |
1 | // 通用的事件绑定函数--简版 |
事件代理
事件代理是指将子元素的事件绑定到父元素上处理
应用场景:无限下拉的图片,点击每个图片的事件处理效果相同,此时如果给每一个元素绑定相同的事件处理函数就太浪费资源了,而且代码也太冗余了,利用事件代理就可以在其父元素上统一监听,绑定一次即可
1 | //html结构 |
1 | // 通用的事件绑定函数--简版 |
AJAX
jQuery:https://blog.csdn.net/xianhenyuan/article/details/92669817
Fetch: https://developer.mozilla.org/zh-CN/docs/Web/API/Fetch_API/Using_Fetch
- 手写一个简易的ajax
- 跨域的常用实现方式
XMLHttpRequest
XMLHttpRequest是浏览器的API,所以在使用时需要结合html文件,在浏览器中打开,否则会报错(直接在node.js环境中使用就会报错)
GET
1 | //1 实例化 |
POST
1 | //1 实例化 |
promise写法
1 | function ajax(url) { |
状态码
xhr.readyState
- 0-(未初始化)还没有调用send()方法
- 1-(载入)已调用send()方法,正在发送请求
- 2-(载入完成) send()方法执行完成,已经接收到全部响应内容
- 3-(交互)正在解析响应内容
- 4-(完成)响应内容解析完成,可以在客户端调用
xhr.status
- 2xx-表示成功处理请求,如200
- 3xx–需要重定向,浏览器直接跳转,如301 302 304
- 4xx-客户端请求错误,如404 403
- 5xx -服务器端错误
跨域
同源策略,
跨域解决方案
JSONP
CORS
存储
描述cookie localStorage sessionStorage区别
- 容量
- API易用性
- 是否跟随http请求发送出去
cookie
- cookie可以实现存储的原因是,在页面刷新时,cookie的值不会清零,但是cookie本身不是用来存储的
- cookie的缺点
- 存储有限,最大4KB
- 每次http请求时都需要将cookie发送到服务端,增加了请求数据量
- 只能用
document.cookie= ‘..’来修改,该接口太过简陋,使用不方便
localStorage和sessionStorage
HTML5专门为存储而设计,最大可存5M
API简单易用setItem getItem
- 以键值对的形式存储
1 | localstorage.setItem( 'a', 100) |
- 不会随着http请求被发送出去
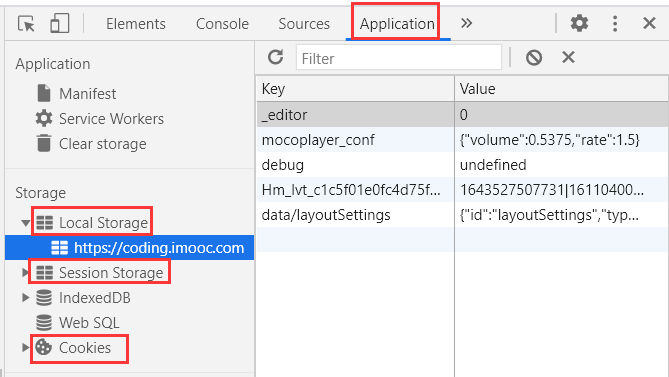
- localStorage和sessionStorage区别
- localStorage 数据会永久存储,除非代码或手动删除 ,(多用此方法)
- sessionStorage数据只存在于当前会话,浏览器关闭则清空
HTTP
- http常见的状态码有哪些?
- http常见的header有哪些?
- 什么是 Restful API
- 描述一下http的缓存机制(重要)
http code
状态码分类
- 1xx服务器收到请求
- 2xx请求成功,如200
- 3xx重定向,如302(该服务端已不工作,请求其他地址)
- 4xx客户端错误,如404(请求的地址错误)
- 5xx服务端错误,如500(服务端代码错误)
常见状态码
- 200 OK - [GET]:服务器成功返回用户请求的数据
- 201 CREATED -[POST/PUT/PATCH]:用户新建或修改数据成功
- 204 NO CONTENT - [DELETE]:用户删除数据成功。
- 301永久重定向(配合location ,重定向的地址存储在location中,浏览器自动处理,下次请求直接请求重定向的地址)
- 302临时重定向(配合location,浏览器自动处理,下次请求还是请求原地址,返回302后再去请求新地址,百度搜索案例)
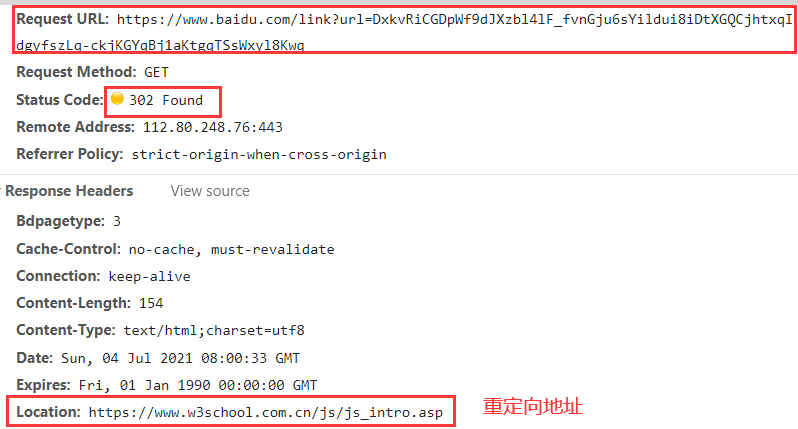
- 304资源未被修改(刚才已经请求过了,且内容没有变化,服务端不会再次发送内容,客户端使用之前的内容即可)
- 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。
- 403 Forbidden - [*]表示用户得到授权(与401错误相对),但是访问是被禁止的。
- 404资源未找到(请求地址错误)
- 500服务器错误(代码错误)
- 504网关超时(数据库操作超时,服务端多个服务器之间交互超时)
http methods
传统methods
- get获取服务器的数据
- post向服务器提交数据
现状methods
- get 获取数据
- post 新建数据
- patch 更新数据
- put 更新数据
- delete 删除数据
1 | //案例 |
Restful API
—种新的API设计方法(早已推广使用)
传统API与Restful API的区别
- 传统API设计:把每个url当做一个功能
- Restful API设计:把每个url当做一个唯一的资源的id(url是资源的唯一标识)
Restful API设计的特点
不使用url参数
- 传统API 设计:
/api/list?pageIndex=2 - Restful API设计:
/api/list/2
- 传统API 设计:
用method表示操作类型
1 | //传统API 设计 |
1 | //Restful API设计 |
http headers
- 常见的Request Headers(客户端传给服务端的头信息)
- Accept浏览器可接收的数据格式
- Accept-Encoding浏览器可接收的压缩算法,如gzip
- Accept-Languange浏览器可接收的语言,如zh-CN
- Connection: keep-alive 长链接:一次TCP连接重复使用
- cookie
- Host 请求地址的域名
- User-Agent (简称UA)浏览器信息
- Content-type发送数据的格式,如application/json
- 常见的Response Headers(服务端返回客户端的头信息)
- Content-type返回数据的格式,如application/json
- Content-length返回数据的大小,多少字节
- Content-Encoding返回数据的压缩算法,如gzip
- Set-cookie
http 缓存
- 什么是缓存?(对不需要重复获取的资源存储在本地)
- 为什么需要缓存?(提升响应速度,减少资源浪费)
- 哪些资源可以被缓存?—静态资源( js css img )
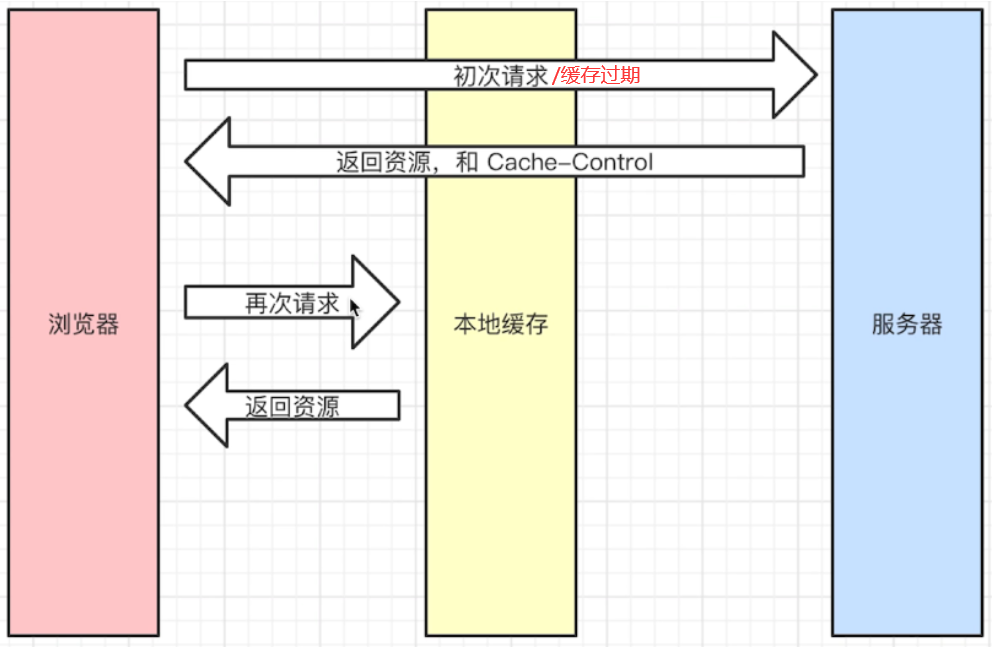
强制缓存
Expires已经被Cache-Control代替
强制缓存就是设定可以缓存的时间(max-age),只要不超过这个时间,每次请求都会从缓存中读取,不会发送请求
使用场景:例如百度的图标,短期不会变化,大概率不会存在缓存时间内数据会被修改的可能,即使修改问题也不大,则可以用强制缓存的方式
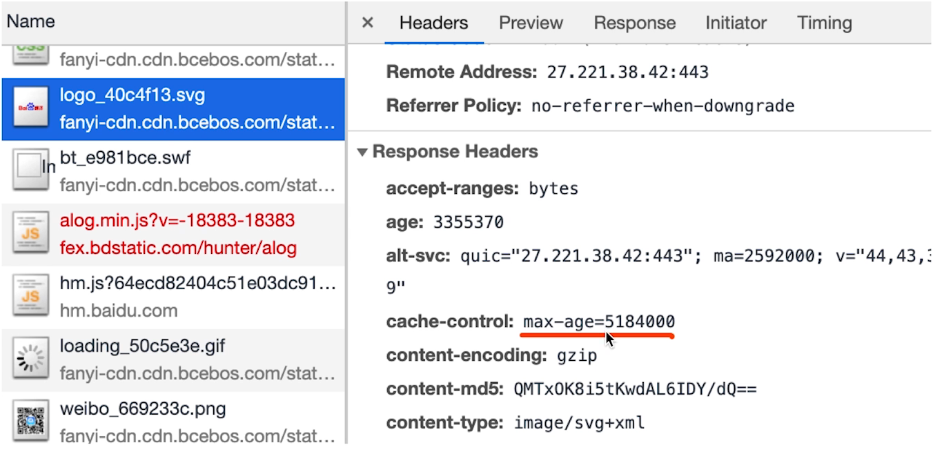
Cache-Control
- Response Headers中
- 控制强制缓存的逻辑
- 例如Cache-Control: max-age=3153600(单位是秒) 控制可缓存的最大时长
- Cache-Control的值
- max-age (控制可缓存的最大时长)
- no-store (不允许强制缓存也不允许协商缓存)
- no-cache (只是不允许强制缓存)
- public (终端用户的设备可缓存,路由过程中也可缓存)
- private (只允许终端用户的设备可缓存)

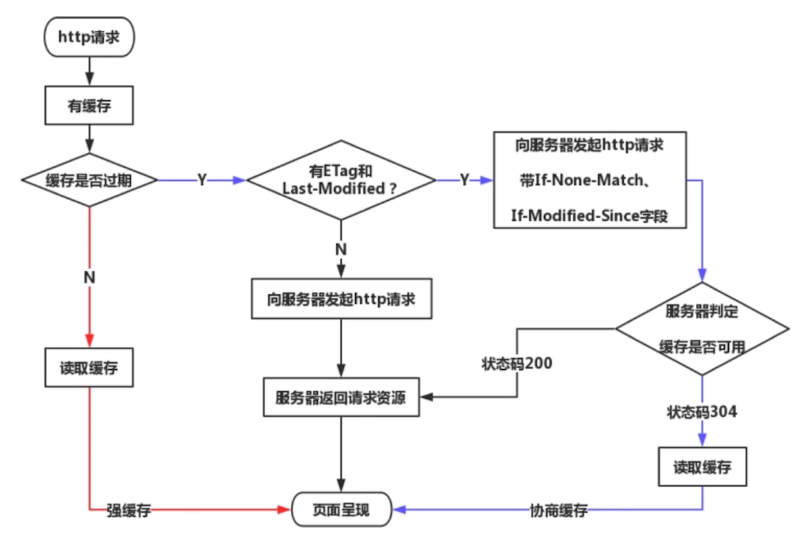
协商缓存
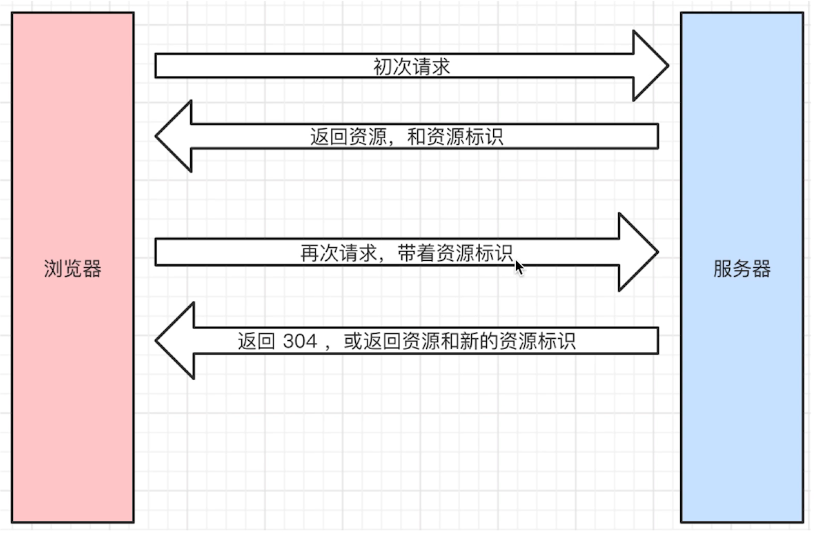
协商缓存是一种服务器端缓存策略
- 服务器判断客户端资源是否和服务端资源一样,若一致则返回304(资源未被修改),否则返回200和最新的资源
- 判断资源是否一致的方式是对比资源标识是否发生变化
资源标识
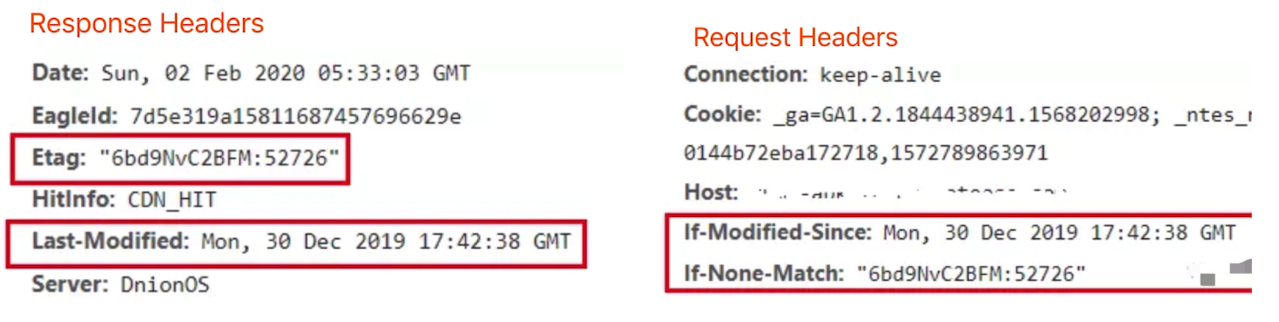
在Response Headers中,有两种
- Last-Modified资源的最后修改时间
- Etag资源的唯一标识(一个字符串,是通过内容计算出来的,只要内容没变,字符串就不变)
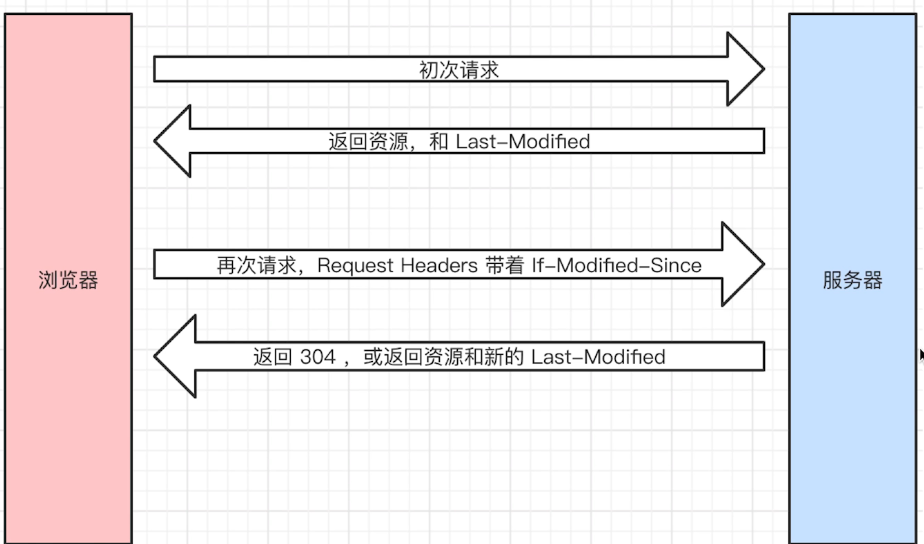
- Last-Modified的情况
- If-Modified-Since的值就是Last-Modified的值
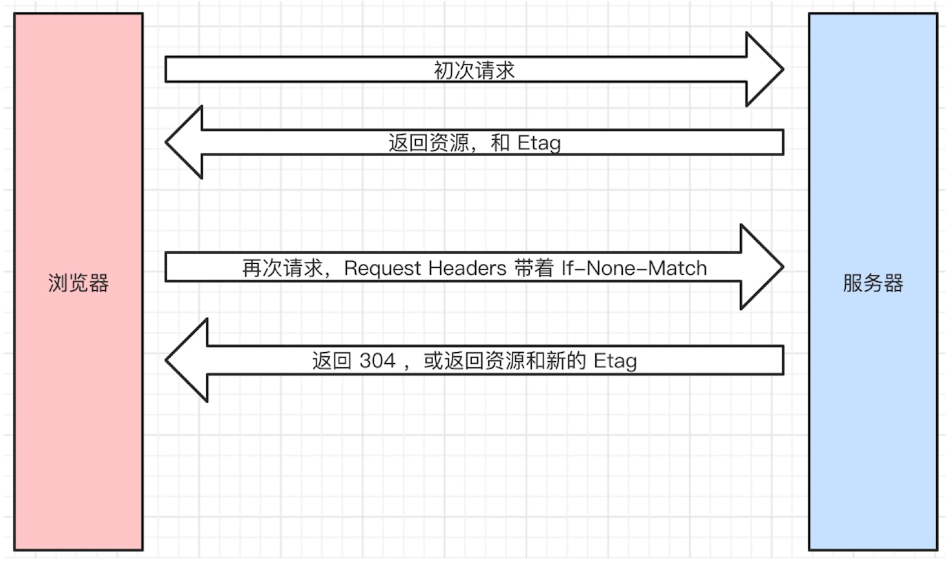
- Etag的情况
- If-None-Match的值就是Etag的值
- Last-Modified和Etag
- 会优先使用Etag
- Last-Modified只能精确到秒级,存在一秒内多次修改的情况,这种情况Last-Modified就不能记录了
- 如果资源被重复生成,而内容不变(内容是周期性更新的,但更新可能并没有真的需要修改的内容),则Etag更精确,因为Etag是根据内容生成的字符串
- Last-Modified和Etag可以同时使用
缓存流程图
三种刷新操作
- 正常操作:地址栏输入url , 跳转链接,前进后退等
- 手动刷新: F5 ,点击刷新按钮;右击菜单刷新
- 强制刷新: ctrl + F5
- 正常操作:强制缓存有效,协商缓存有效
- 手动刷新:强制缓存失效,协商缓存有效
- 强制刷新:强制缓存失效,协商缓存失效
开发环境
git
常用命令
git add .
git checkout xxx 恢复到修改前的状态(撤销修改)
- git checkout 文件名 恢复这个文件的修改
- git checkout . 恢复所有文件的修改
- 已经git add 的文件则不能再撤销修改,只要是还没有加入缓存区的都可以修改
- 只能撤销修改的文件,不能撤销新建的文件
git commit -m “xxx”
git push origin master 提交到远程服务器
git push orgin 新分支名 在远程新建分支并将本地此分支提交到远程(此操作包括在远程新建分支和提交分支)
git pull origin master
git branch 查看分支
git checkout -b xxx 新建分支并切换到该分支上
git checkout xxx 切换分支
git merge xxx 合并分支
git diff 查看文件修改的具体内容
- git diff 文件名 查看单个文件的修改内容
- git diff 不加文件名 查看所有的文件修改内容
- git add 之后再执行git diff 就无效了,只有在未加入缓存区之前,才能查看修改的内容
git show + 版本号 查看这个版本修改的具体内容
- 先通过 git log 找到版本号
git log 查看提交的版本,
- 此时是对已经git add 和git commit 后的版本查看,
- 若没有git commit 则无效,本质是对git commit 的版本进行查看
git fetch 访问远程仓库,从中拉取所有本地还没有的数据
git stash 将修改的部分移除并暂存在其他地方(误操作时使用)
- git stash pop 推出暂存的部分
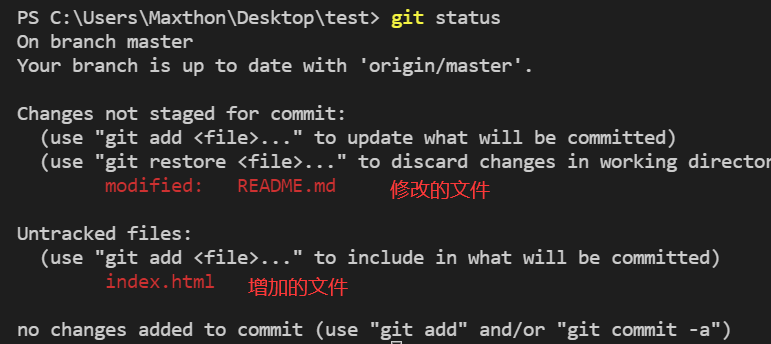
git status 查看当前状态(可以查看修改了哪些文件,新增加了哪些文件,此时还没提交版本)
- 文件修改,或文件添加后已经保持,但还没有git add ,此时文件标红
- git add 后,此时文件标绿
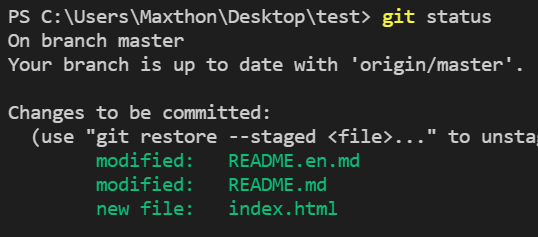
- git commit 后,此时就看不到修改的文件和添加的文件了,只会显示已提交x个版本
多人开发
leader创建项目,此时项目为master分支
开发者1 需要开发登陆功能
拉取master分支的代码到本地:
git clone新建分支并切换到该分支进行开发:
git checkout -b login//login为新分支名修改或添加文件,完成开发
将开发完成的代码提交到远程服务器:
git push origin login//在远程新建login分支并将本地该分支提交到远程
开发者2 需要开发注册功能
拉取master分支的代码到本地:
git clone新建分支并切换到该分支进行开发:
git checkout -b register//login为新分支名修改或添加文件,完成开发
将开发完成的代码提交到远程服务器:
git push origin register//在远程新建register分支并将本地该分支提交到远程
leader合并开发者1和2的代码
leader在master分支上,拉取最新内容
git fetch切到需要合并的分支上
git branch不会显示开发者新建的分支名,可以在远程查看分支名
然后直接执行
git checkout 分支名就直接切换到分支上了,而且本地分支和远程分支是一一对应的
切到分支后,拉取最新代码:
git pull orgin 分支名//此操作是确保每个分支是最新内容合并分支(终端切在master分支上):
git merge login//将login分支内容合并到master分支上将合并后的代码推到远程服务器:
git push按以上步骤合并下一个分支,直到产生冲突

- 找到冲突文件的位置,选择保留方式,并修改冲突位置
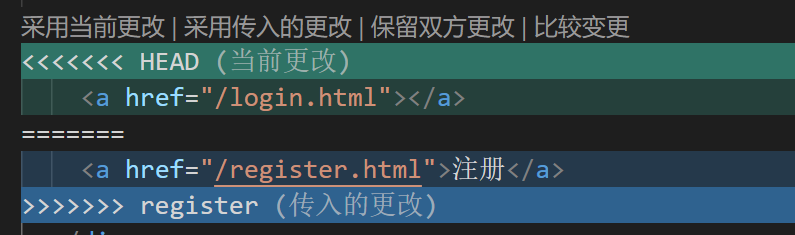
* 因为处理冲突后修改了文件内容,所以需要`git add git commit`
* 提交到远程服务器: `git push`误操作
拉取master分支后,本来是要新建分支再开发,但是忘记新建分支就直接在master分支上开发了
- 以下操作是在没有加入暂存区之前执行才有效
- 执行完以下操作后,master恢复到没有开发前的状态
- 将已经在master上开发的部分移除并暂存到其他地方:
git stash - 新建分支并切到相应分支上:
git checkout -b 新分支 - 将暂存的部分推出到新的分支上:
git stash pop - 将修改的部分暂存到暂存区并提交本版再推到远程:
gti add、 git commit、 git push origin 新分支
webpack babel
ES6模块化,浏览器暂不支持
ES6语法,浏览器并不完全支持
压缩代码,整合代码,以让网页加载更快
webpack打包流程
安装node.js
项目根目录下初始化:
npm init -y- 初始化后根文件夹下会生成文件
package.json
- 初始化后根文件夹下会生成文件
安装webpack:
npm install --save-dev webpack webpack-cli- 使用 webpack 4+ 版本,还需要安装 CLI
根目录下新建资源文件夹(src)即入口文件(index.js)
src/index.js
根目录下新建配置文件
webpack.config.js,并配置入口和出口1
2
3
4
5
6
7
8
9
10
11
12
13
14//webpack.config.js
const path = require('path')
module.exports = {
//development是开发模式,production是生产模式(上线模式)
mode: 'development',//production
//入口:可以是字符串、数组、对象,这里只有一个入口,写字符串即可
entry:'./src/main.js',
//出口: path:打包文件保存路径 filename:打包的文件名
output:{
path: path.resolve(__dirname,'dist'),
filename: 'bundle.js'
}
}package.json中定义打包启动
1 | //package.json |
- 打包
1 | npm run build |
打包index.html
目前的index.html文件是存放在项目的根目录下的。
- 在真实发布项目时,发布的是dist文件夹中的内容,但是dist文件夹中如果没有index.html文件,那么打包的js等文件也就不能起效果
- 所以,需要将index.html文件打包到dist文件夹中,这个时候就可以使用
HtmlWebpackPlugin插件
HtmlWebpackPlugin插件的功能:- 自动生成一个index.html文件(可以指定模板来生成)
- 将打包的js文件,自动通过script标签插入到body中
安装
HtmlWebpackPlugin插件
1 | npm install html-webpack-plugin --save-dev |
使用插件,修改webpack.config.js文件中plugins部分
- 这里的template表示根据什么模板来生成index.html
- fielname是在dist文件夹中生成的文件名
1 | //webpack.config.js |
搭建本地服务
webpack提供了一个可选的本地开发服务器,这个本地服务器基于node.js搭建,内部使用express框架,可以实现浏览器自动刷新显示我们修改后的结果。
安装
1 | npm install --save-dev webpack-dev-server@版本号 |
webpack.config.js中配置
devServer- contentBase:为哪一个文件夹提供本地服务,默认是根文件夹,一般指定./dist
- port:端口号
- inline:页面实时刷新
- historyApiFallback:在SPA页面中,依赖HTML5的history模式
1 | module.exports = { |
package.js中配置
scripts该配置是设置启动本地服务器的命令
--open: 表示直接打开浏览器
1 | "scripts": { |
- 启动本地服务器
1 | 终端:npm run dev |
webpack配置分离
webpack配置分离详细教程:Chuckie’Blog-webpack
开发模式转生成模式的简易操作流程
- 新建webpack.prod.js,将webpack.config.js的内容复制到该文件并做如下修改
- 去掉devServer的配置(因为上线的产品不需要本地服务)
- output和mode做如下修改
1 | //webpack.config.js |
- package.json修改
- 重定向打包的配置文件
1 | "scripts": { |
ES6转ES5(待完成)
模块化 导入导出
ES6 export import
使用前提: script type类型为module
1 | <script src='../text.js' type='module'></script> |
- 导出:export: 逐一导出
1 | export let myName = "Tom"; |
- 导出:export: 统一导出,等同于逐一导出
1 | let myName = "Tom"; |
- 导出:export: export default
- 在一个文件或模块中,export、import 可以有多个,export default 仅有一个。
- export default 中的 default 是对应的导出接口变量。
- 通过 export 方式导出,在导入时要加{ },export default 则不需要。
- export default 向外暴露的成员,可以使用任意变量来接收。
1 | var a = "My name is Tom!"; |
1 | //导出 |
- 导入:import: 导入时 路径一定是相对路径
1 | 1 逐个导入 |
- 导入:import: as用法
1 | /*-----export [test.js]-----*/ |
对比commonJS模块
使用前提:需要node.js环境解析 所以 使用前要先安装node.js
导出
1 | module.exports = {变量名,函数名,对象名} |
- 导入
1 | let {变量名,函数名,对象名} = require('../aaa.js') |
- 别名
1 | //导出 |
1 | //导入 |
linux常用命令
本地登陆linux账户:
ssh 主机名@地址查看文件
- 平铺:
ls - 列表形式:
ll - 查看所有文件(包括隐藏文件):
ls -a
- 平铺:
清屏:
clear创建文件夹:
mkdir ...删除文件夹:
rm -rf ...-r: 递归删除-f:强制删除
删除文件:
rm 文件名切换文件夹:
cd 文件夹名/后退:cd ../修改文件名:
mv 原文件名 新文件名移动文件:
mv 文件名 新路径(相对路径)/文件名拷贝:
cp 被拷贝文件名 拷贝文件名新建文件
touch 文件名//只新建vi 文件名或vim 文件名//新建并打开- 键盘点击
i进入编辑模式,可以编辑文件 - 点即
ESC按键,再输入:,再输入w(写入),再回车,再输入q(保存),再回车即可保存文件并推出 - 点即
ESC按键,再输入:,再输入q,强制推出,之前修改的内容并没有保存
- 键盘点击
查看文件内容
vi 文件名 或 vim文件名: 可打开还可修改cat 文件名: 只能查看文件head 文件名: 查看文件头部内容tail 文件名: 查看文件尾部
在文件中查找关键字:
grep "关键字" 文件名
抓包(待完成)
移动端h5页,查看网络请求,需要用工具抓包
windows一般用fiddler
Mac oS一般用charles
- 抓包流程
- 手机和电脑连同一个局域网
- 将手机代理到电脑上
- 手机浏览网页,即可抓包
运行环境
页面加载过程
- 从输入url到渲染出页面的整个过程
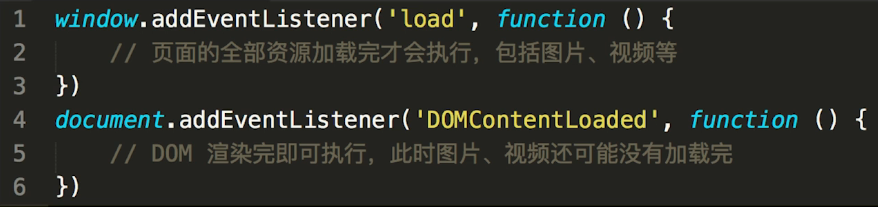
- window.onload和DOMContentLoaded的区别
- 在页面渲染时(根据render tree渲染页面时),遇到图片(img标签)或视频加载时,不会阻断渲染,渲染会继续,只是图片的位置会预留处理,当图片、视频加载完成后会将图片、视频放到预留的位置,而图片加载时间可能长于渲染时间,所以会出现渲染已经完成,但时图片还未加载完成的情况
- 加载资源的形式
- html代码
- 媒体文件:图片、视频等
- javascript 、css代码
- 加载资源的过程
- DNS解析:域名->IP地址
- 浏览器根据IP地址向服务器发起http请求(建立TCP链接,再发送请求)
- 服务器处理http请求,并返回给浏览器
- 渲染页面的过程
- 根据HTML代码生成DOM Tree
- 根据CSS代码生成CSSOM Tree
- 将DOM Tree和CSSOM Tree整合形成Render Tree
- 根据Render Tree渲染页面
- Layout(回流):根据生成的渲染树,进行回流(Layout),得到节点的几何信息(位置,大小)
- Painting(重绘):根据渲染树以及回流得到的几何信息,得到节点的绝对像素
- 调用GPU触发渲染,将结果展示在页面上
- 遇到
<script>则暂停渲染,优先加载并执行js代码,完成再继续 - 直至把Render Tree渲染完成
性能优化
性能优化原则
- 多使用内存、缓存或其他方法
- 减少CPU计算量,减少网络加载耗时
- (适用于所有编程的性能优化——空间换时间)
让加载更快
- 减少资源体积︰压缩代码
- 例如:生产模式下webpack打包生成的bundle.js文件就是压缩文件
- 减少访问次数∶合并代码,SSR服务器端渲染,缓存
- SSR 此处不懂,待完成???????
- 服务器端渲染:将网页和数据一起加载,一起渲染
- 非SSR(前后端分离):先加载网页,再加载数据,再渲染数据
- 早先的JSP ASP PHP,现在的vue React SSR
- 合并代码案例:生产模式下webpack打包生成的bundle.js文件就是多个js文件合并后的文件
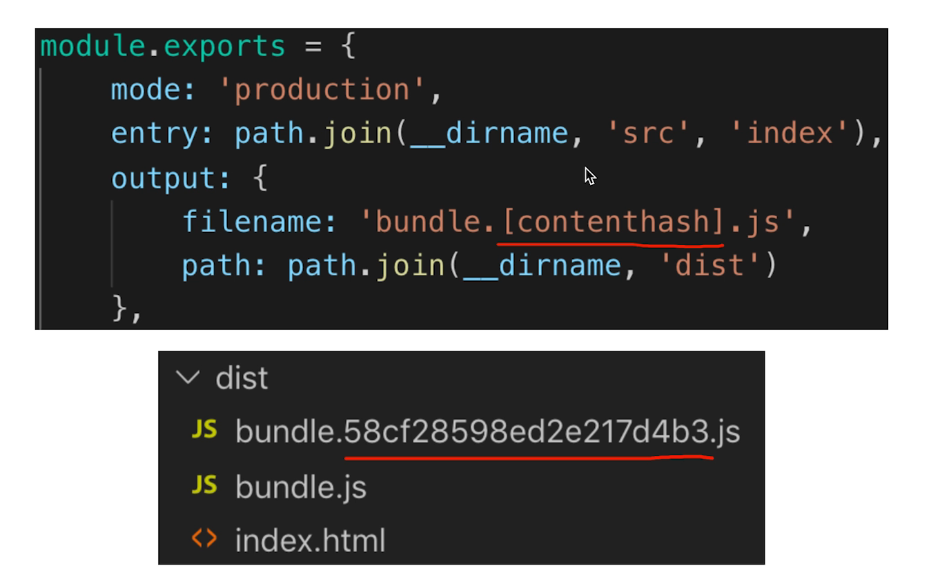
- 缓存案例:这里http缓存机制需要设置
Etag或Last-Modified吗?????- webpack打包的静态资源加hash后缀,根据文件内容计算hash
- 文件内容不变,则hash 不变,则url不变
- url和文件不变,则会自动触发http缓存机制,返回304
- SSR 此处不懂,待完成???????
- 使用更快的网络:CDN 此处不懂,待完成???????
让渲染更快
- CSS放在head ,JS放在body最下面
- 尽早开始执行JS,用DOMContentLoaded触发
- 懒加载(图片懒加载,上滑加载更多)
1 | //src="preview. png" 是占位图片,data-realsrc="abc.png"是图片的真实地址 |
- 对DOM查询进行缓存
- 频繁DOM操作,合并到一起插入DOM结构
节流throttle
函数节流: 规定在一个单位时间内,事件响应函数只能被触发一次。如果这个单位时间内触发多次函数,只有一次生效
频繁操作频繁触发事件—>无论操作多频繁都设定每隔n毫秒触发一次事件
使用场景:
window.onresize事件
- 网页大小变化时触发事件,右上角全屏和小窗口的切换,或者拖动窗口大小的变化
mousemove事件
拖拽一个元素时,要随时拿到该元素被拖拽的位置
直接用drag事件,则会频发触发,很容易导致卡顿
节流:无论拖拽速度多快,都会每隔100ms触发一次
1 | //throttle.html |
1 | //throttle1.js |
防抖debounce
防抖函数:事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时
频繁操作频繁触发事件—>在频繁操作结束并停顿n毫秒后触发事件
案例(搜索框)
- 监听一个输入框时,文字变化后触发change事件
- 直接用keyup事件,则会频发触发change事件
- 防抖∶用户输入结束或暂停时,才会触发change事件
1 | //debounce.html |
1 | //debounce1.js |
安全
XSS跨站请求攻击
XSS又叫CSS (Cross Site Script) ,跨站脚本攻击。
- 案例
- 一个博客网站,我发表一篇博客,其中嵌入
<script>脚本 - 脚本内容:获取cookie ,发送到我的服务器(服务器配合跨域)
- 发布这篇博客,有人查看它,我轻松收割访问者的cookie
- 一个博客网站,我发表一篇博客,其中嵌入
- 预防xss攻击
- 1 对输入的数据进行过滤或转码
- 替换特殊字符,如
<变为<,>变为> <script>变为<script>,直接显示,而不会作为脚本执行- 前端要替换,后端也要替换,都做总不会有错
- 替换特殊字符,如
- 2 csp (利用同源策略)
- 3 使用HttpOnly属性
- 服务端设置cookie的HttpOnly属性为true, 表示在浏览器不能访问cookie
- 1 对输入的数据进行过滤或转码
- 案例
XSRF 跨站请求伪造(CSRF(Cross-site request forgery)跨站请求伪造)
- 案例
- 你正在购物,看中了某个商品,商品id是100
- 付费接口是xxx.com/pay?id=100,但没有任何验证
- 我是攻击者,我看中了一个商品,id是200
- 我向你发送一封电子邮件,邮件标题很吸引人
- 但邮件正文隐藏着<img src=xXx.com/pay?id=200 /> 此时你的浏览器是存储了购买商品的网站的个人信息(例如cookie)即验证信息的
- 你一查看邮件,就帮我购买了id是200的商品
- 预防xsrf攻击
- 使用post接口(post接口实现跨域很复杂,需要服务端验证,所以直接用img标签是攻击不了的)
- 增加验证,例如密码、短信验证码、指纹等
- 案例
补充知识点
正则表达式
1 |
|
面试真题
var和let const 的区别
var 和let是变量,可修改;const是常量,不可修改;
let const 有块级作用域,var没有
var是 ES5语法,let const是ES6语法;var有变量提升
1 | // 变量提升 ES5 |
typeof 返回哪些类型
- undefined string number boolean symbol
- object (注意,typeof null === ‘object’)
- function
列举强制类型转换和隐式类型转换
- 强制: parseInt parseFloat toString 等
- 隐式:if、逻辑运算、==、+拼接字符串
手写深度比较,模拟lodash isEqual
1 | // 判断是否是对象或数组 |
- split()和join()的区别
1 | '1-2-3'.split('-')//[1,2,3] |
数组的pop push unshift shift分别做什么
- pop: 删除数组最后一个元素,返回值:删除的元素
- shift: 删除数组第一个元素,返回值:删除的元素
- push: 在数组最后添加元素,返回值:添加元素后的数组长度
- unshift: 在数组最前添加元素,返回值:添加元素后的数组长度
数组API有哪些是纯函数
纯函数:1.不改变源数组(没有副作用); 2.返回一个数组
1 | const arr = [10, 20, 30, 40] |
- 数组的常见非纯函数
1 | //非纯函数 |
- 数组slice和splice的区别
1 | const arr = [10, 20, 30, 40, 50] |
[10,20,30].map(parseInt)返回结果是什么?
parseInt是将radix进制的字符串string转换为十进制整数
若不传参数radix则传入上面进制的数就返回什么进制的数,只是去掉小数点后的部分,只保留整数部分
1 | const res = [10, 20, 30].map(parseInt) |
- ajax请求get和post的区别?
- get一般用于查询操作,post 一般用户提交操作
- get参数拼接在url 上 , post放在请求体内(数据体积可更大)
- 安全性:post易于防止XSRF
- 函数call和apply的区别
- 传参方式不一样
- 事件代理(委托)是什么?
- 闭包是什么,有什么特性?有什么负面影响?
- 闭包就是能够读取其他函数内部变量的函数
- 特性∶函数作为参数被传入,函数作为返回值被返回
- 特性: 自由变量的查找,要在函数定义的地方(而非执行的地方)
- 影响:变量会常驻内存,得不到释放。闭包不要乱用
- 如何阻止事件冒泡和默认行为?
- event.stopPropagation()
- event.preventDefault()
- 查找、添加、删除、移动DOM节点的方法?
- 如何减少DOM操作?
- 缓存DOM查询结果
- 多次DOM操作,合并到一次插入
- 解释jsonp的原理,为何它不是真正的ajax ?
- jsonp是利用
<script>请求到一段js代码(代码是可以已经包含了数据)并直接执行 - 因为jsonp没有使用xmlhttprequestAPI,没有服务端允许跨域的步骤
- jsonp是利用
- document load和ready的区别
- load: 图片、视频加载完成后
- ready: 渲染完成后,但图片、视频可能还未加载完
DOMContentLoaded
- ==和===的不同
- == 会尝试类型转换
- === 严格相等 值和类型都一样
- 函数声明和函数表达式的区别
- 函数声明
function fn() {...} - 函数表达式
const fn = function() {...} - 函数声明会在代码执行前预加载,而函数表达式不会
- 函数声明
1 | // 函数声明 |
1 | // 函数表达式 |
- new Object()和Object.create()的区别
- {}等同于new Object() ,原型为Object.prototype
- Object.create(null)没有原型
- Object.create({…})可指定原型
Object.create({...})新建一个空对象,并让空对象的隐式原型等于传入的值
1 | const obj1 = { |
- 关于this的场景题
- this在执行的时候确定,不是在定义的时候确定
1 | const User = { |
- 关于作用域和自由变量的场景题
1 | let i |
1 | let a = 100 |
- 判断字符串以字母开头,后面字母数字下划线,长度6-30
1 | const reg = /^[a-zA-Z]\w{5,29}$/ |
手写字符串trim保证浏览器兼容性
trim():去除字符串两边的空白
replace():在字符串中查找匹配的子串,并替换与正则表达式匹配的子串。返回值:修改后的字符串
1 | 先判断是否有String.prototype.trim。若没有则做下面操作以达到兼容的效果 |
获取多个数字中的最大值
使用Math.max() 或下面的函数
1 | function max() { |
- 如何捕获JS程序中的异常?
1 | //高风险位置 |
1 | //自动捕获 |
- 什么是JSON ?
- json是一种数据格式 ,本质是一段字符串。
- json格式和JS对象结构一致,对JS语言更友好
- window.JSON是一个全局对象: JSON.stringify JSON.parse
- JSON中key和字符串都要用双引号
- 获取当前页面url参数
1 | //url:http://code/questions-demo/index.html?a=10&b=20&c=30 |
- 将url参数解析为JS对象
1 | //传统方式,分析search |
手写数组flat, 考虑多层级
将多维数组变成一维数组
some(): 检测数组元素中是否有元素符合指定条件
- 如果有一个元素满足条件,则表达式返回true , 剩余的元素不会再执行检测。
- 如果没有满足条件的元素,则返回false。
1 | function flat(arr) { |
- 数组去重
- 推荐使用set的方式,因为传统方式forEach和indexOf都是遍历,就形成了嵌套遍历,时间复杂度更大
1 | // 传统方式 |
- 手写深拷贝
- 注意, Object.assign不是深拷贝! 它只拷贝了第一层,更深层的只拷贝了引用
- 介绍一下RAFrequestAnimationFrame
- 要想动画流畅,更新频率要60帧/s , 即16.67ms更新一次视图
- setTimeout要手动控制频率,而RAF浏览器会自动控制
- 后台标签或隐藏iframe中, RAF会暂停,而setTimeout依然执行
1 |
|
1 | ///RAF.js |
- 前端性能如何优化?- -般从哪几个方面考虑?
- 原则:多使用内存、缓存,减少计算、减少网路请求
- 方向:加载页面,页面渲染,页面操作流畅度
浏览器渲染原理
will-change: https://blog.csdn.net/Mancuojie/article/details/120632389
浏览器渲染:https://www.yuque.com/i_geek/rules
chrome浏览器源码: http://www.taodudu.cc/news/show-1646530.html?action=onClick
浏览器渲染流程
1 | 1、使用htm1解析器将htm1页面转换成浏览器能够理解的DOM树ParseHTML |
那几情况能被叫做图层
1 | 1、css 3d |
浏览器一次可以接受多少数据
- 64kb, 很大的视频也是分段接收
HTTP
http/1.0: 解决多种类型文件下载―通过请求头和响应头进行协商、增加cache ,状态码,用户代理
http/1.1:对文件传输的速度,持久化连接,用户提升连接效率。
http/2.0:
为什么HTTP/1.1很难将带宓占满
1 tcp的慢启动 (http1.1允许一个域名开6个tcp)
2 同时开启多条TCP连接,那么这些连接会竞争国定的带宽
3 http/1.1的队头阻塞问题
基于以上问题就提出了HTTP/2.0
多路复用技术:一个域名只使用一个TCP长连接来传输数据
1 解决了tcp慢启动的问题,因为只有1个tcp了
2 解决了tcp竞争的问题
3 增加了优先级,解决了队头阻塞的问题,优先响应高优先级的数据
4 增加服务推送,请求html的时候,服务端知道html中引用了css,js,则提前将这些css,js推送给客户端
5 增加了头部压缩
浏览器安全
每日一题
页面变黑白
1 | filter: grayscale(1); // 1 是黑白, 0 是彩色, (0,1)之间,,, |